Serverless
Deploy serverless applications on CoreWeave Cloud
CoreWeave Cloud enables clients to run their own code, manage data, and integrate applications - all without ever having to manage any infrastructure.
Deploying serverless applications is an especially ideal deployment alternative when the purpose of the application is to serve HTTP or gRPC requests either internally or externally to and from the Internet.
- The Applications Catalog houses tons of apps that you can deploy with a few clicks!
- Learn more about the benefits of Serverless Kubernetes and how it works.
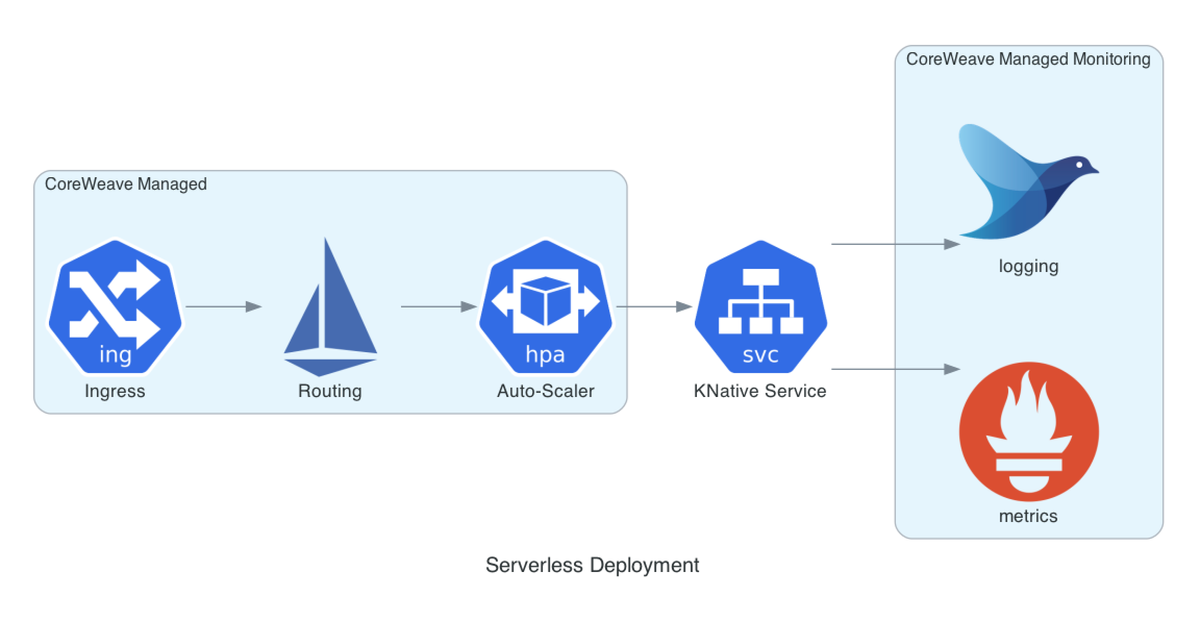
Knative on CoreWeave
CoreWeave uses the Knative runtime to support deploying serverless applications with a single manifest, so no additional installation or configuration is necessary to deploy your applications.
Serverless benefits
🔐 Automatic public HTTPS endpoints
Never worry about managing SSL certificates for your serverless applications - with Knative and LetsEncrypt, HTTPS endpoints are automatic with every deployment.
📈 Autoscaling by default, including Scale-to-Zero
High-availability comes built-in with serverless application deployments on CoreWeave, so application resources scale automatically according to their traffic. Scaling to zero means consuming no resources, incurring no billable charges while idle.
💰 No charge for public IPs
Public IP addresses do not incur any additional costs when deploying serverless applications on CoreWeave, making public distribution of the application easy.
🧪 Advanced deployment strategies
CoreWeave's implementation of the Knative runtime supports advanced deployment strategies, including traffic splitting techniques useful for blue/green and canary deployment methods.
Deployment example
The following example manifest demonstrates how to deploy a simple application manifest onto CoreWeave Cloud.
apiVersion: serving.knative.dev/v1 # Current version of Knativekind: Servicemetadata:name: helloworld # The name of the appspec:template:metadata:annotations:autoscaling.knative.dev/minScale: "0" # Allow scale to Zeroautoscaling.knative.dev/maxScale: "10" # Maximum number of Pods allowed to auto-scale tospec:# The container concurrency defines how many active requests are sent to a single# backend pod at a time. This configuration is important as it affects how well requests# are load balanced over Pods. For a standard, non-blocking web application, this can usually# be rather high, ie 100. For GPU Inference however, this should usually be set to 1.# GPU Inference only processes one request at a time, and one wants to avoid a queue being# built up in the local pod instead of centrally in the Load Balancer.containerConcurrency: 1containers:- image: gcr.io/knative-samples/helloworld-go # The URL to the image of the appresources:limits:cpu: 2memory: 4Gienv:- name: TARGET # The environment variable printed out by the sample appvalue: "Go Sample v1"
containerConcurrency defines how many active requests are sent to a single backend Pod at a time. This configuration is important, as it affects how well incoming requests are load balanced over Pods.
For a standard, non-blocking web application, this can usually be a high number, i.e. 100. For GPU Inference, however, this should usually be set to 1, as GPU Inference only processes one request at a time. Setting containerConcurrency to 1 avoids forming a queue in the local Pod, instead of centrally in the Load Balancer.
Ingress options
CoreWeave supports two ingress options for Knative serving: Kourier and Istio. Kourier is the default option and is recommended for most use cases.
Kourier is the default Knative serving ingress and does not require additional annotation to use. However, the Kourier annotation may be added for the sake of explicitness.
To specify an ingress type to the Service, use the networking.knative.dev/ingress-class annotation, set to one of these values:
| Ingress | Annotation value |
|---|---|
| Kourier (default) | kourier.ingress.networking.knative.dev |
| Istio | istio.ingress.networking.knative.dev |
The annotation must be added at creation, and can not be changed afterwards.
| Ingress | Annotation value |
|---|---|
| Kourier (default) | kourier.ingress.networking.knative.dev |
| Istio | istio.ingress.networking.knative.dev |
If electing to use Istio instead of Kourier, annotate the Service's ingress class (networking.knative.dev/ingress-class) with istio.ingress.networking.knative.dev, as shown below.
apiVersion: serving.knative.dev/v1 # Current version of Knativekind: Servicemetadata:name: helloworld # The name of the appannotations:networking.knative.dev/ingress-class: istio.ingress.networking.knative.dev # Use Istio...
Service URL
Once the manifest is applied and the application is deployed, get the public URL of the Service using kubectl get ksvc:
$kubectl get ksvcNAME URL LATESTCREATED LATESTREADY READY REASONhelloworld https://helloworld.default.knative.ord1.coreweave.com helloworld-ngzsn helloworld-ngzsn True
URL endings will vary depending on the ingress in use:
| Ingress | URL ending |
|---|---|
| Kourier (default) | .ord1.coreweave.cloud |
| Istio | .chi.coreweave.com |
If the URL provided does not use https, it may be that the domain is too long and therefore unable to acquire an SSL certificate. Domains must be at or under a total of 64 characters in order to successfully provision SSL. For further assistance, please contact your CoreWeave Support Specialist.
Monitoring
Managed Grafana monitoring provides insights into requests, success rates, response times and auto-scaling metrics transparently. No metrics-specific code needs to be added to the serverless application.
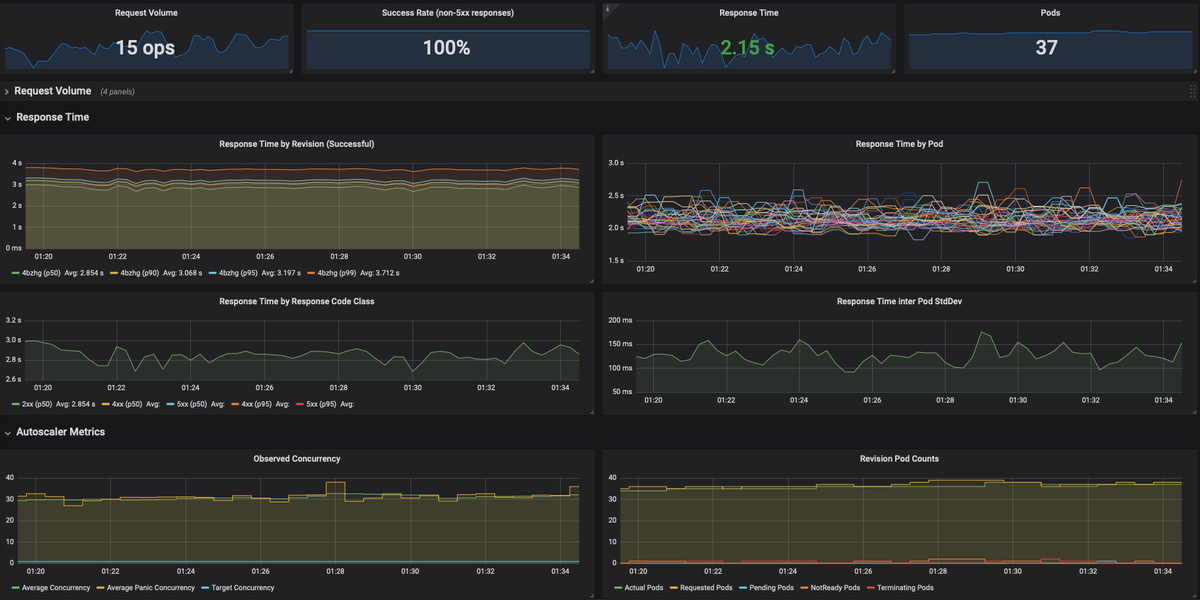
To access Grafana, log in to your CoreWeave Cloud account, then navigate to the Account Details section in the left-hand navigation menu, and click Grafana. Clicking this link will open a new window in your browser.
 (4).e820ecd.448.png)