

Concepts
The Slurm Topology/Block Plugin adds new features for managing job placement within NVLink domains. Key concepts include Blocks, Segments, and the--exclusive=topo option.
When SUNK auto-generates the topology file, it defines Blocks based on the ds.coreweave.com/nvlink.domain label on CKS Nodes. For GB200 and GB300 NVL72-powered Nodes, this label is a globally unique rack identifier, for example, DH4-016-US-EAST-02A.
In clusters with both NVLink-enabled multi-Node systems and standard Nodes, SUNK creates a topology.conf file that includes Block and switch definitions. This configuration doesn’t affect behavior unless you explicitly enable the Topology/Block Plugin, which ensures safe integration and runtime flexibility.
Blocks
A Block is a group of Nodes in the same Slurm cluster, defined in thetopology.conf file. SUNK automatically generates this file, so you don’t need to create or manage it manually. It specifies which Nodes belong to each Block and defines the Block size, the minimum number of Nodes in a Block.
Each Block has a unique ID and cannot overlap with others. CoreWeave dynamically updates the topology configuration to reflect changes in Node availability. By default, each GB200 or GB300 NVL72-based system corresponds to a Block containing 18 Nodes in the same NVLink domain. If any Nodes become unhealthy, the CoreWeave platform removes them from the SUNK cluster. However, the block size stays fixed at 18. As a result, some Blocks may temporarily have fewer than 18 available Nodes.
Segments
A Segment is a set of Nodes within a Block that Slurm allocates together. It must fit within a single Block and cannot cross Block boundaries. Segments reduce resource fragmentation because they keep allocations intact. If a job spans multiple Blocks, Slurm schedules equal-sized Segments in each Block. A Block can hold multiple Segments if space allows. By default, if you don’t provide a segment size, Slurm uses the full Block size. The following are best practices when configuring segment size:-
When you select a segment size for your job, default to
--segment=1. This makes your job more flexible because it can run on any available Nodes across all Blocks, which improves scheduling efficiency. -
On GB200 NVL72 systems, don’t use a segment size larger than
--segment=16. This gives a buffer for Nodes to fail on a rack before it becomes unusable for your job. - Balance segment sizes across jobs on your cluster with factors of 16 (8, 4, 2, 1). This minimizes the number of idle Nodes on each rack left unavailable to your jobs.
-
Always set the segment size explicitly. If you omit the segment size, Slurm defaults to
--segment=18. This adds additional scheduling constraints and can cause submission failures.
Exclusive option
The--exclusive=topo option ensures that only the job being submitted runs in a Block. The job won’t share a Block with any other job, and no new jobs can be placed there until the original job completes. Unused Nodes in the Block remain idle. Use this option for benchmarking or to avoid resource competition.
Example scenarios
The following scenarios show how to use the Topology/Block Plugin to optimize job placement within GB200 and GB300 NVL72-based systems. Use them as reference patterns when sizing your own jobs and choosing segment sizes. Each diagram shows multiple 18-Node NVL72 systems (Blocks). Node colors represent status:- Green: Nodes running the requested job (light green indicates a second job or Segment)
- Gray: Unavailable: drained, down, or running unrelated jobs
- White: Idle
A job that fits in a Block
A job requests 10 Nodes, which is less than the Block size. The segment size is set to 1, following best practice.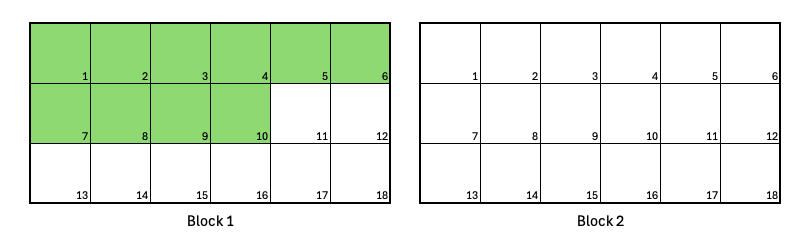
Job requests 10 Nodes.
Jobs larger than the Block size
A job requests 20 Nodes, which exceeds the Block size of 18. The segment size is set to 1, following best practice.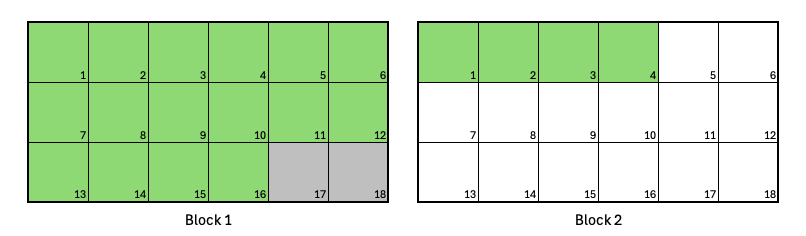
Job requests 20 Nodes
Two jobs in a single Block
You submit two jobs. The first requests 8 Nodes, and the second requests 4. The segment size is set to 1 for both jobs, following best practice.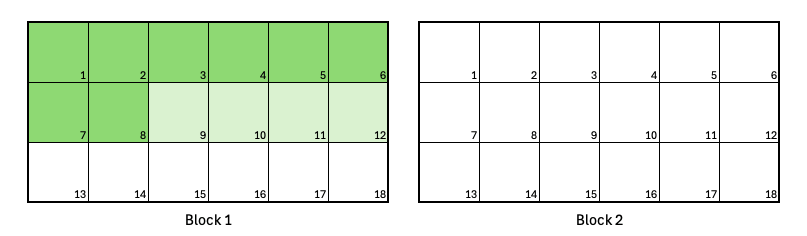
Two jobs can fit in a single Block
Realistic training example: A job with two Segments
A job requests 32 Nodes, divided into two Segments of 16 Nodes each.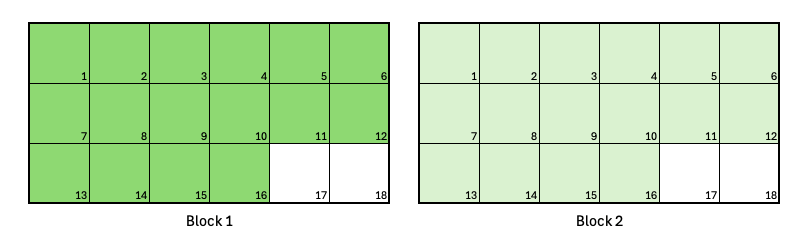
A job with two Segments
Exclusive jobs
A job requests 16 Nodes with the--exclusive=topo option. The segment size is set to 1, following best practice.
--exclusive=topo prevents it from running in Block 1 while a competing job (light green) is active. The rest of Block 2 remains idle, and no other jobs can run there until this job completes.
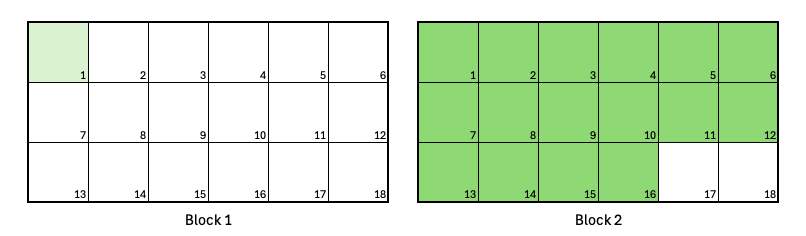
Exclusive jobs
Combining Segments and the exclusive option
A job requests 16 Nodes, divided into two 8-Node Segments, using--exclusive=topo.
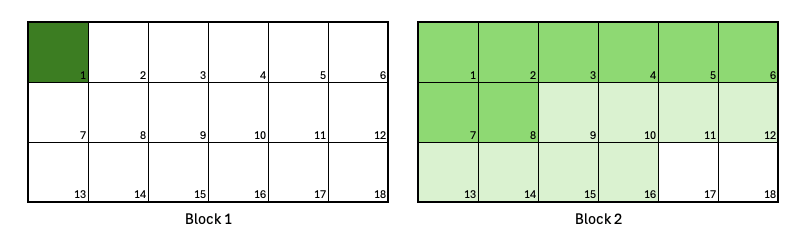
Combining Segments and Exclusive jobs
Identify idle Nodes in a Block
Before you submit a job, you can check how many Nodes are currently idle in each Block to choose a segment size that schedules promptly. Use the script at/usr/share/sunk/bin/segment-calc.sh on the Slurm login node to check for idle Nodes within a Block. By default, it reports idle Nodes per topology Block. You can optionally provide the --segment N argument to report only those Blocks with at least N idle Nodes available.