For instructions about accessing CoreWeave Grafana dashboards, see Access and use CoreWeave Grafana dashboards.
- Monitor the GPU and CPU utilization of a given Slurm job.
- Track the rate of filesystem operations related to the Slurm job.
- View Node conditions and alerts that may impact the performance of the Slurm job.
Filters and parameters
Use these filters at the top of the page to choose the data you want to view:
The dashboard also includes buttons with links to the SLURM / Namespace dashboard and
slurmctld logs.
Set the time range and refresh rate parameters at the top-right of the page. The default time range is 5 minutes, and the default refresh rate is 1 minute.
Panel descriptions
The following sections describe each group of panels on the dashboard, starting with Job Info and continuing through GPU Metrics, Filesystem, and Node Resources.Job Info
The Job Info section displays identifying information about the selected Slurm job, including:Estimate model flop utilization (MFU) from tensor core utilization
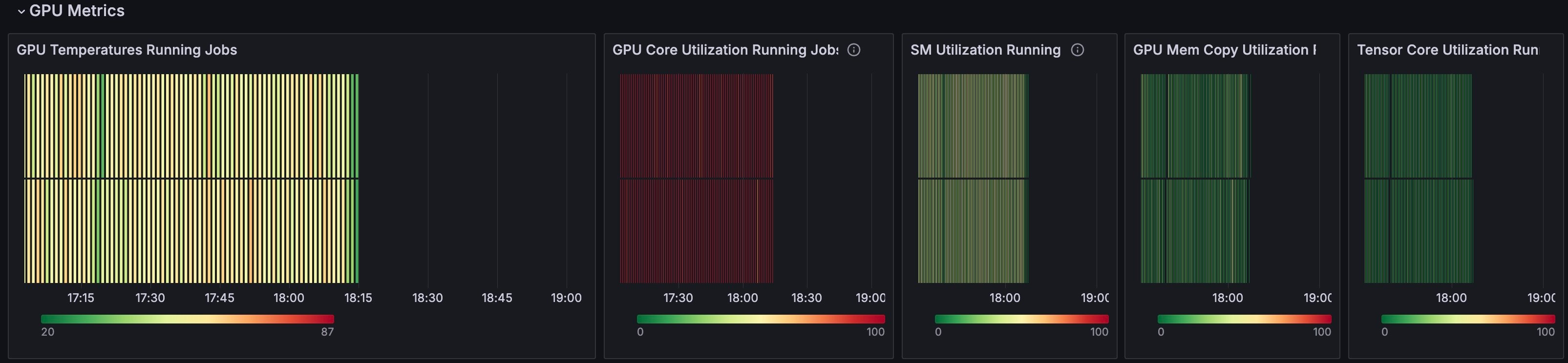
Use the Tensor Core Utilization Running Jobs panel in the GPU Metrics section to get a rough estimate of MFU.
Job Info: Job State Timeline and Last State
The Job Info section contains panels that display information about the state of the selected Slurm job. Last State displays the most recent reported state, while the Job State Timeline displays the job’s status over time.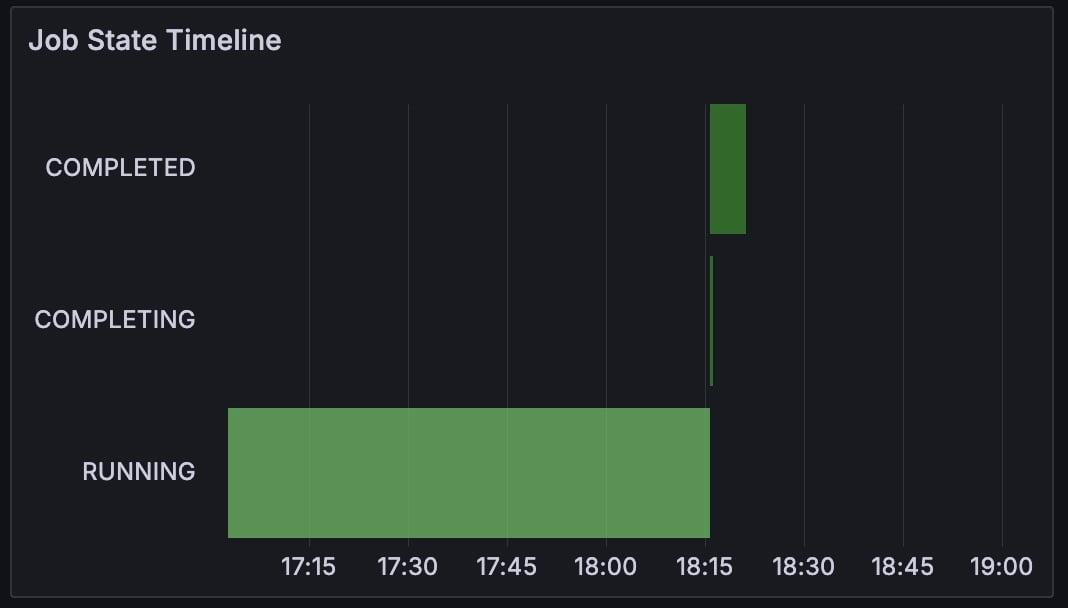
Job Info: Node alerts
Job alerts in the Slurm Job / Metrics dashboard are generated by CoreWeave’s Mission Control, an automated system that continuously monitors and manages the underlying compute infrastructure to maintain high cluster reliability and availability. These alerts target hardware and system-level issues, such as GPU errors, networking failures, and endpoint timeouts. These conditions aren’t typically observable through application-layer metrics such as training metrics or standard logs.Understanding Node alerts and conditions
The following image shows an interruption caused by a Node alert, namelyGPUContainedECCError.
- Blue lines: Indicate Node conditions.
- Red lines: Indicate Node alerts.
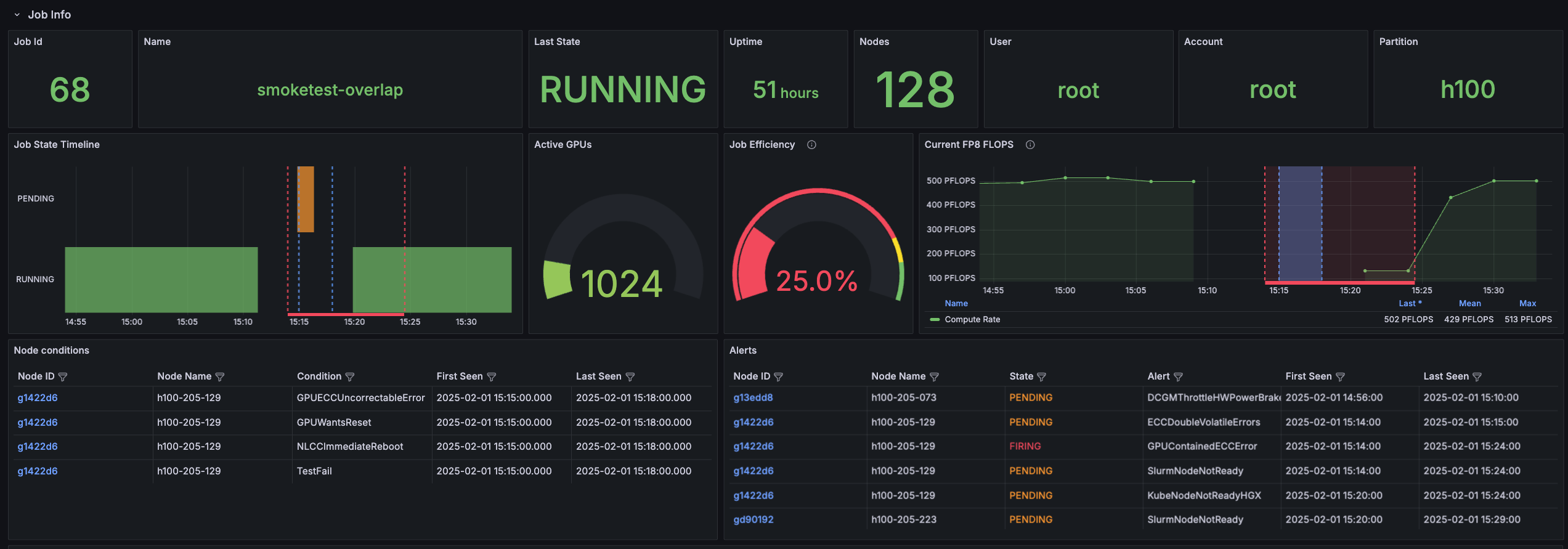
GPUContainedECCError, appears before the drop in compute, while the Node conditions indicated by the blue lines delineate the window the drop in compute occurred within.
The image shows that the H100 cluster experienced a hard fault around 15:15. Throughput dropped from 500 PFLOPS to 0 because the Slurm scheduler pulled a Node out of the pool due to a GPUContainedECCError. Understanding how Node alerts and conditions are overlaid on Node metrics can help you diagnose and troubleshoot problems with a running job.
GPU Metrics
The GPU Metrics section displays detailed information related to hardware utilization. In this section, red lines correspond with higher temperature or utilization of the measured value, while green lines indicate a lower value or idle state. Whether these values suggest “good” or “bad” performance depends on the expected behavior and resource utilization of the job.GPU Metrics: Color coding
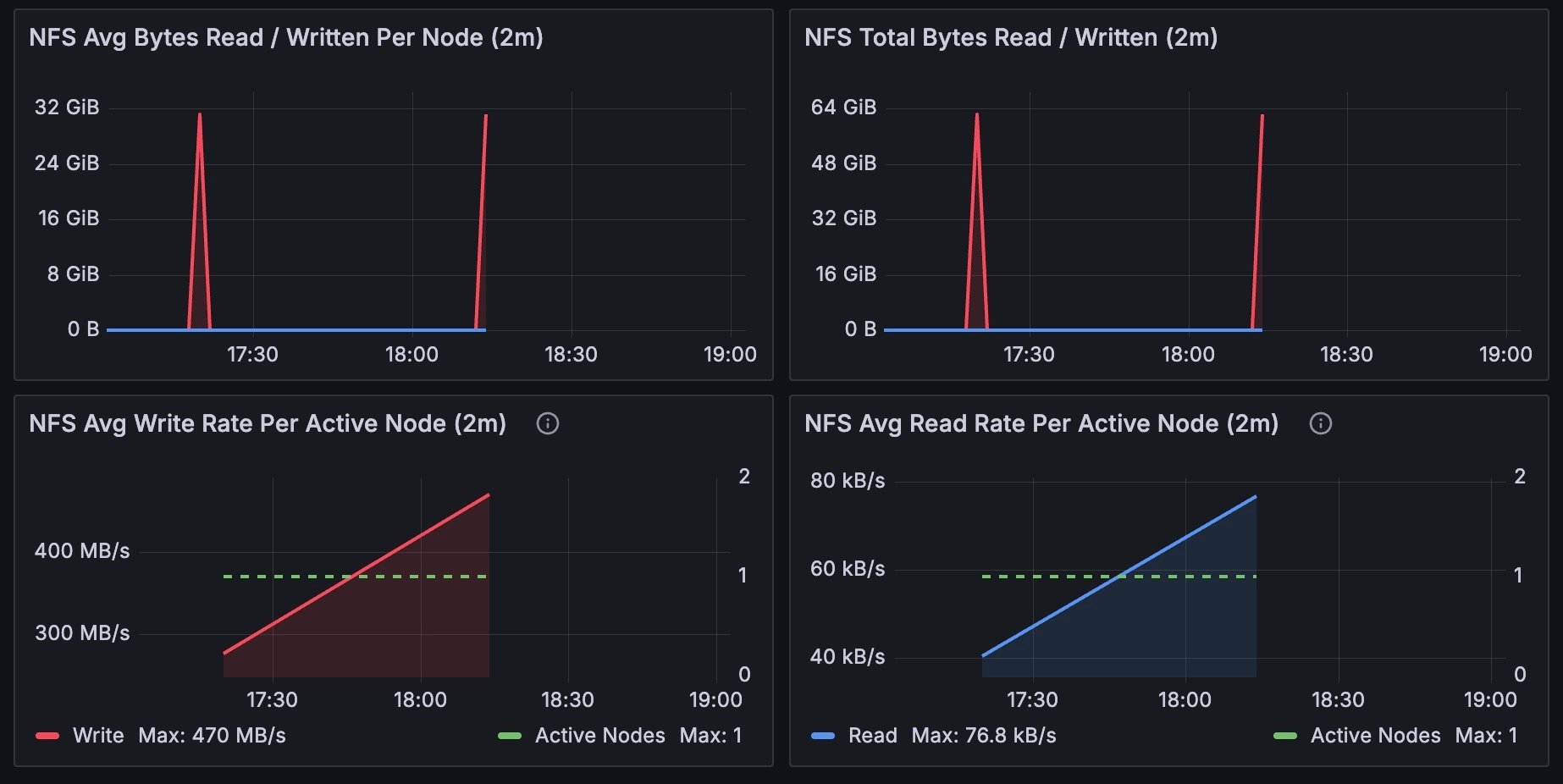
write operations.
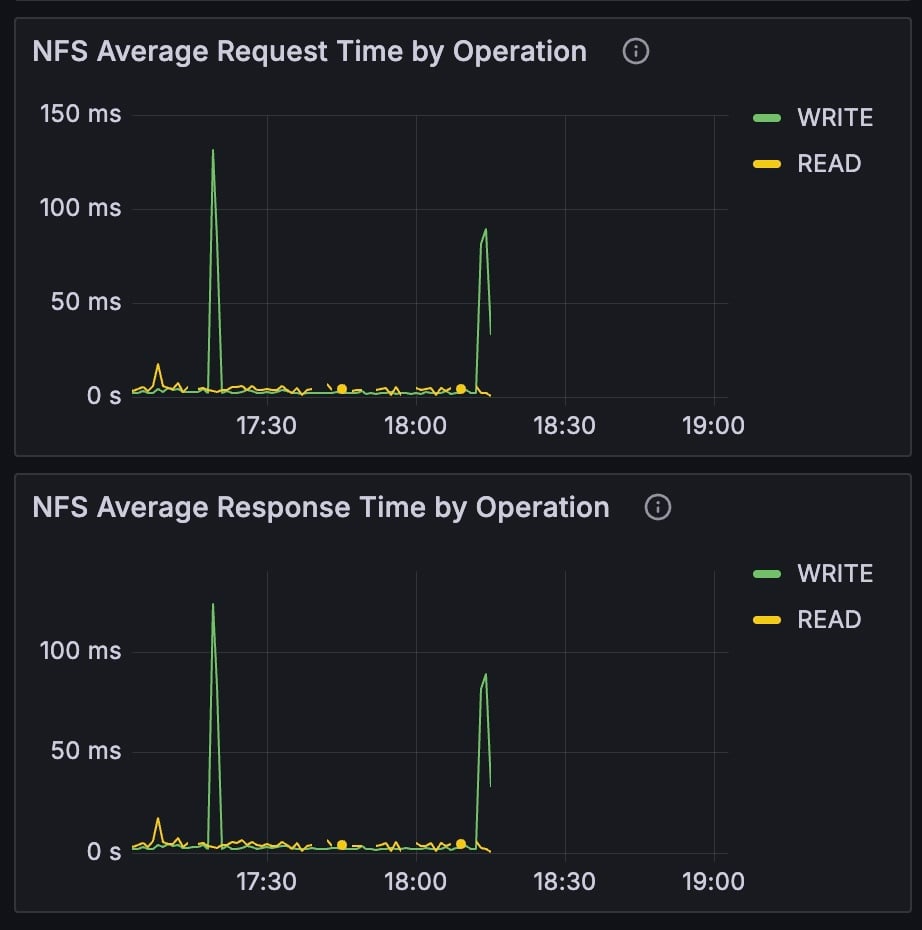
Filesystem
The Filesystem section includes information aboutread and write operations on the Network File System (NFS) and local files.