

For instructions about accessing CoreWeave Grafana dashboards, see Access and use CoreWeave Grafana dashboards.
- Monitor the resource usage of SUNK jobs across all clusters.
- Track the rate of filesystem operations of SUNK jobs across all clusters.
- View information about SUNK jobs on a per-user or per-partition basis.
Filters and parameters
Use these filters at the top of the page to choose the data you want to view:
The dashboard also includes a button with a link to the SLURM / Job Metrics dashboard.
Set the time range and refresh rate parameters at the top-right of the page. The default time range is 5 minutes, and the default refresh rate is 1 minute.
Panel descriptions
The following sections describe the dashboard panels, grouped by category.Slurm jobs
The Slurm Jobs section lists information about the Slurm jobs running in the selected Namespace. It includes panels that display the jobs according to status.Slurm jobs: Running jobs

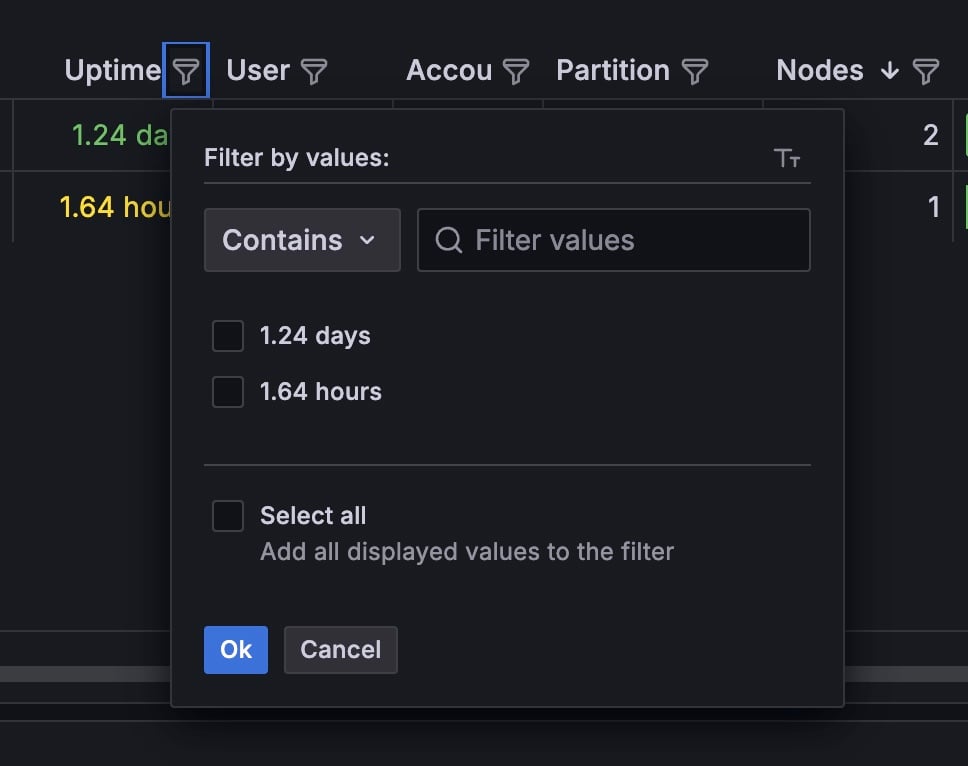
The
Count field at the bottom of the table displays the total number of running jobs.
Control plane health
The Control Plane Health section displays status information about the Control Plane components.Slurm-Login info
The Slurm-Login Info section includes three panels:Nodeset status
The Nodeset Status panel displays pods by availability. The graph is color-coded with the following scheme:Cluster nodes
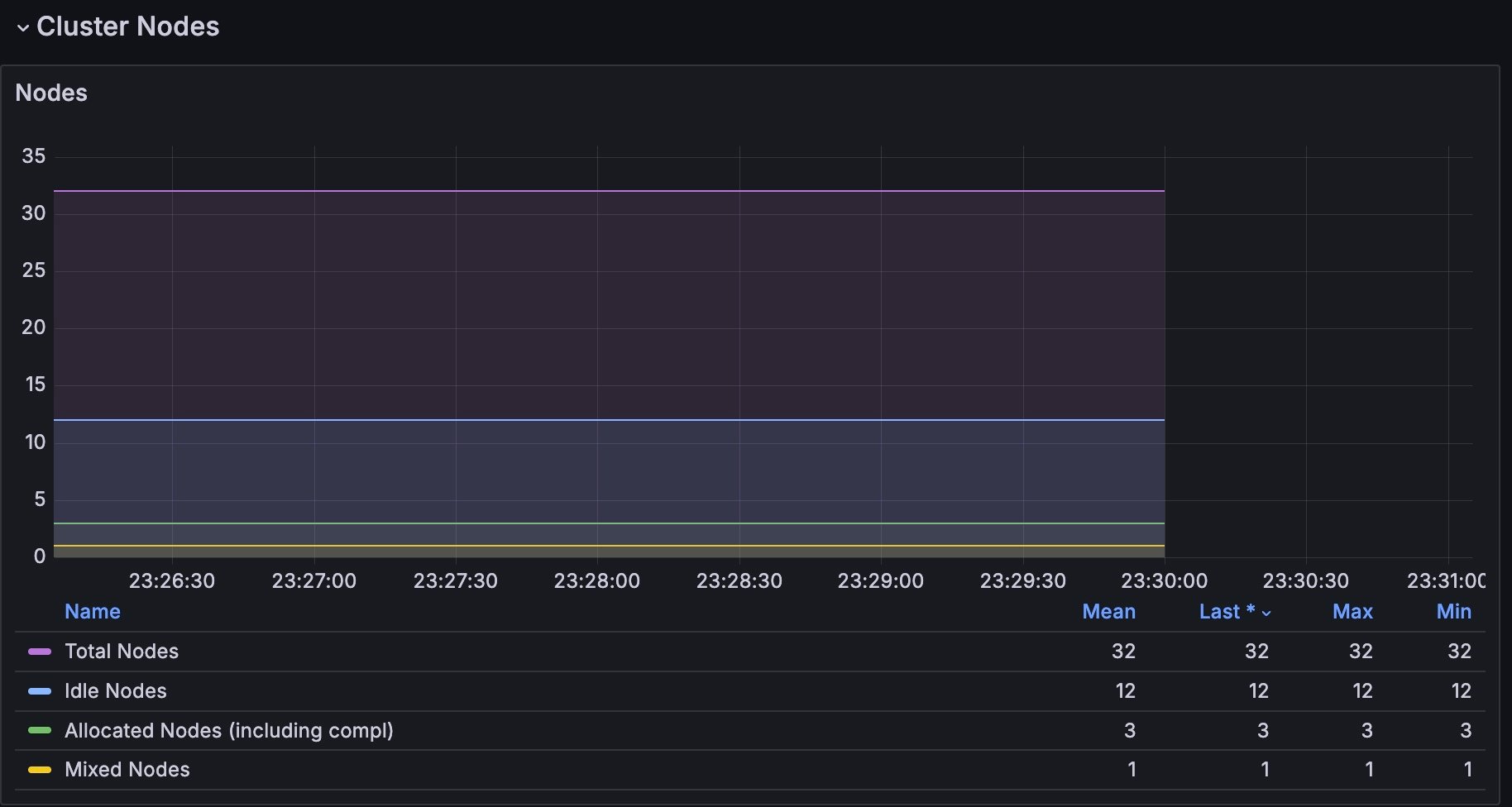
GPU metrics
The GPU Metrics section has four panels: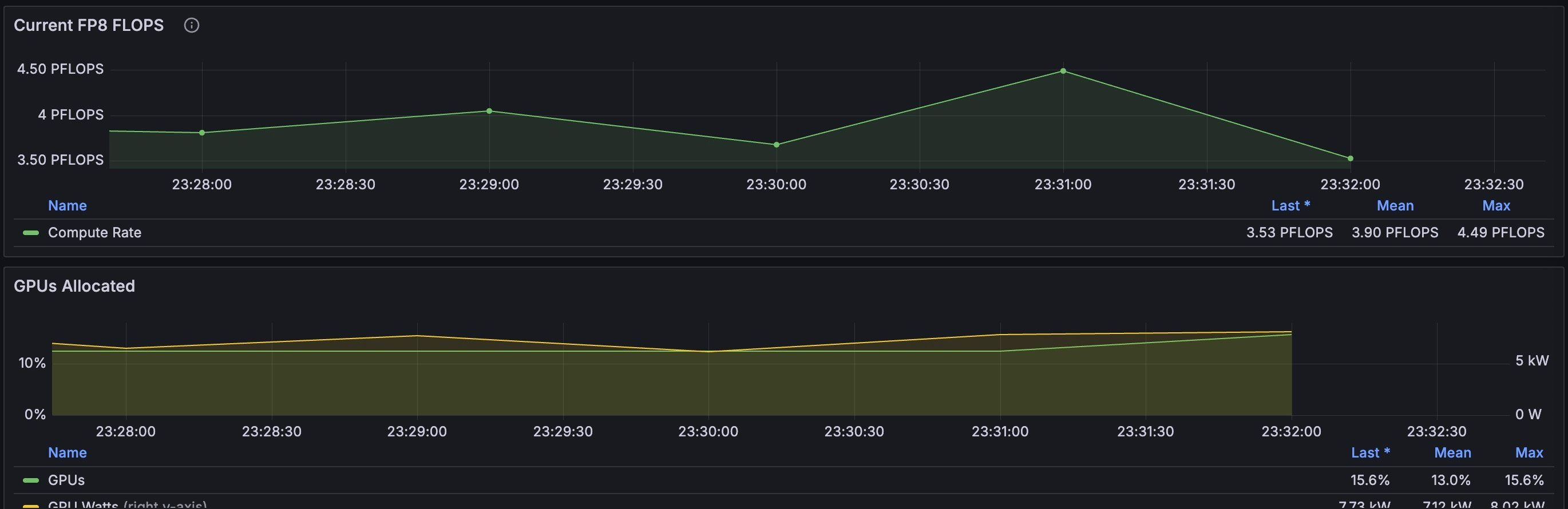
Filesystem
The Filesystem section includes information aboutread and write operations on the Network File System (NFS) and local files.