Argo Workflows
How to use Argo Workflows to run jobs in parallel
This guide provides an introduction to Argo Workflows, outlines the steps needed to deploy the application on CoreWeave Cloud, and gives a quick walkthrough of the web UI.
If you are experienced with Argo Workflows and only need CoreWeave Cloud deployment details, skip ahead to the deployment section.
.4f979a0.373.png)
After deploying Argo Workflows, see our other guides with deeper dives into security best practices, Argo's Command Line Interface (CLI), the REST API, and how to submit workflows with Helm. We also have valuable tips to enhance performance and ensure workflows are resilient.
To see practical examples that use Argo Workflows on CoreWeave Cloud, jump to the Examples section.
What is Argo Workflows?
Argo Workflows is a powerful, open-source workflow management system available in the CoreWeave Applications Catalog.
It's used to define, execute, and manage complex, multi-step workflows in a code-based manner. It's developed and maintained as a Cloud Native Computing Foundation (CNCF) Graduated project, and uses the principles of cloud-native computing to ensure scalability, resiliency, and flexibility. Some of its key features are:
- Workflow definition using YAML: Workflows are defined using a human-readable YAML format, which can be easily version-controlled and integrated into CI/CD pipelines. This allows users to create and modify workflows as code, enabling automation and collaboration across teams.
- Directed Acyclic Graph (DAG): Argo Workflows uses a directed acyclic graph to model workflow execution, allowing for complex dependencies and parallelism. This ensures that each step in the workflow is executed in a specific order, and parallel tasks can be run simultaneously to optimize processing time.
- Container-based tasks: Argo Workflows runs tasks within containers, which provides isolation and allows for the use of different environments and runtime configurations. This makes it easy to build, package, and share tasks as container images, ensuring consistency and reproducibility.
- Scalability: Built on top of Kubernetes, Argo Workflows can automatically scale resources according to workload demands. This ensures efficient resource utilization and allows for the execution of large-scale workflows without manual intervention.
- Fault-tolerance and high availability: Argo Workflows provides mechanisms for handling failures, retries, and timeouts, ensuring that workflows can recover from errors and continue executing. Additionally, it leverages the resilience and high availability features of Kubernetes, such as self-healing and rolling updates.
- Visualization and monitoring: Argo Workflows offers a web-based user interface that enables users to visualize, monitor, and interact with their workflows. Additionally, it provides integrations with monitoring and logging tools, such as Prometheus and Grafana, for advanced observability.
- Extensibility: Argo Workflows supports custom task executors and integrations with other systems, such as artifact repositories, message queues, and cloud services. This allows users to create and customize workflows that meet their unique requirements.
Argo Workflows can automate repetitive tasks, enable collaboration across teams, and leverage the benefits of CoreWeave's cloud.
How to deploy Argo Workflows
To deploy Argo Workflows, navigate to CoreWeave Applications.
- Click the Catalog tab.
- Search for
argo-workflowsto find the application. - Click Deploy in the upper-right.
- Enter a meaningful name for the deployment, such as
my-workflow. Keep it short and use only lowercase alphanumeric characters, hyphens, or periods, because this becomes part of the ingress URL. - The remaining parameters are set to suggested defaults.
Use client authentication mode
Client authentication mode is strongly encouraged as a security best practice.
.979f664.654.png)
When ready, click the Deploy button at the bottom of the page.
If Expose UI via public Ingress is enabled, the web UI will be accessible from outside the Kubernetes cluster, allowing management of workflows via a web browser.
It may take up to five minutes for the deployment to receive a TLS certificate. Please wait for the certificate to be installed if an HTTPS security warning is shown in the web UI.
How to retrieve the client token
About ServiceAccounts and tokens
When deploying Argo Workflows, three ServiceAccounts are created based on the deployment name. For example, if the name is my-workflow, it creates these:
my-workflow-argomy-workflow-argo-clientmy-workflow-argo-server
This step uses the -argo-client ServiceAccount token. The other ServiceAccounts are described in Security Best Practices for Argo Workflows.
To retrieve the Bearer token for this deployment, run the commands below for the client OS.
- macOS or Linux (bash or zsh)
- Windows PowerShell
# Replace my-workflow with the deployment name.$export ARGO_NAME=my-workflow# Use kubectl to find the name of the secret for the ${ARGO_NAME}-argo-client ServiceAccount.$export SECRET=$(kubectl get sa ${ARGO_NAME}-argo-client -o=jsonpath='{.secrets[0].name}')# Extract the token (a Kubernetes Secret), base64 decode it, and prepend "Bearer " to the string. This is the Bearer token.$export ARGO_TOKEN="Bearer $(kubectl get secret $SECRET -o=jsonpath='{.data.token}' | base64 --decode)"# Display the Bearer token on the screen.$echo $ARGO_TOKEN
# Replace "my-workflow" with the deployment name.>$ARGO_NAME="my-workflow"# Use kubectl to find the name of the secret for the ${ARGO_NAME}-argo-client ServiceAccount.>$SECRET=$(kubectl get sa $ARGO_NAME-argo-client -o=jsonpath='{.secrets[0].name}')# Extract the token (a Kubernetes Secret).>$DATA_TOKEN=$(kubectl get secret $SECRET -o=jsonpath='{.data.token}')# base64 decode the token>$DECODE_64=[System.Text.Encoding]::UTF8.GetString([System.Convert]::FromBase64String($DATA_TOKEN))# Prepend "Bearer " to the string. This is the Bearer token.>$ARGO_TOKEN="Bearer $DECODE_64"# Display the Bearer token on the screen.>Write-Output $ARGO_TOKEN
The Bearer token is used to log into the web UI.
How to use the web UI
The web UI is an interactive way to submit and manage jobs, manage workflows, monitor their progress, and troubleshoot issues. This simplifies the submission and management process, making it efficient to build and run complex workflows.
To get started, navigate to the Argo Workflows deployment in the Applications Catalog, then click the Access URL to open the login page.
.16891f0.935.png)
Paste the Bearer token that was retrieved earlier into the client authentication box, then click Login.
.37d246f.1200.png)
How to submit a new workflow
To submit an example workflow:
- Click +SUBMIT NEW WORKFLOW
- Click Edit using full workflow options
- Delete the existing example YAML.
- Expand the
workflow.yamlbelow, copy/paste it into the Workflow text area, then click +CREATE.
Click to expand - workflow.yaml
apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata:generateName: gpu-sayspec:entrypoint: mainactiveDeadlineSeconds: 300 # Cancel operation if not finished in 5 minutesttlStrategy:secondsAfterCompletion: 86400 # Clean out old workflows after a day# Parameters can be passed/overridden via the argo CLI.# To override the printed message, run `argo submit` with the -p option:# $ argo submit examples/arguments-parameters.yaml -p messages='["CoreWeave", "Is", "Fun"]'arguments:parameters:- name: messagesvalue: '["Argo", "Is", "Awesome"]'templates:- name: mainsteps:- - name: echotemplate: gpu-echoarguments:parameters:- name: messagevalue: "{{item}}"withParam: "{{workflow.parameters.messages}}"- name: gpu-echoinputs:parameters:- name: messageretryStrategy:limit: 1script:image: ghcr.io/coreweave/ml-containers/torch:afecfe9-base-cuda11.8.0-torch2.0.0-vision0.15.1command: [bash]source: |nvidia-smiecho "Input was: {{inputs.parameters.message}}"resources:requests:memory: 128Micpu: 500m # Half a corelimits:nvidia.com/gpu: 1 # Allocate one GPUaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:# This will REQUIRE the Pod to be run on a system with a GPU with 8 or 16GB VRAMnodeSelectorTerms:- matchExpressions:- key: gpu.nvidia.com/vramoperator: Invalues:- "8"- "16"
The Pods begin spinning up:
.881746d.256.png)
A short time later, the workflow should complete.
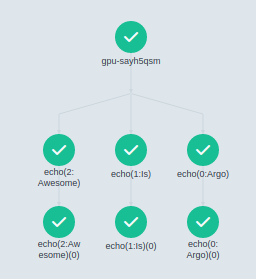
Many other tasks are available in the web UI. For example, use the Workflows menu to manage multiple workflows.
.b2ba587.1200.png)
Much more is possible. Please refer to the Argo Workflows documentation for full details.
Other workflow submission methods
Besides the web UI, it's possible to deploy and manage workflows with the Argo CLI, the Argo REST API, and Helm charts, offering flexibility and control to choose the best approach for each project's requirements.
The Argo CLI can create, submit, manage, and monitor workflows. Reusable templates in YAML files define common parameters and workflow patterns to share across teams.
Argo REST APIThe Argo Workflows REST API powers custom applications with a flexible, language-agnostic interface, and can be integrated into existing CI/CD pipelines and automation workflows.
Helm chartsUse Helm charts to deploy Argo Workflows and manage the configuration. Focus on building and running workflows rather than dealing with the complexities of manual deployment.
All of these methods work in conjunction with the Kubernetes API to create, update, and delete resources such as Pods, Jobs, and ConfigMaps. This tight integration with Kubernetes allows Argo Workflows to leverage all the features and capabilities of the CoreWeave platform, including resource management, scaling, and high availability.
Practical examples
Because Argo Workflows is so powerful, we use it for many Machine Learning and VFX tutorials. Here are a few examples:
- Fine-Tune GPT-NeoX-20B with Argo Workflows
- Fine-tune Stable Diffusion Models with CoreWeave Cloud
- Fine-tune Large Language Models with CoreWeave Cloud
- CGI Rendering with Argo Workflows
More information
For more information about Argo Workflows, please see these resources: