HPC Interconnect
Learn more about HPC Interconnect on CoreWeave Cloud
HPC Workloads are first-class tenants on CoreWeave Cloud. Customers leverage the wide range of GPU availability and seamless access to scale to run parallel jobs, with thousands to tens of thousands of GPUs working together in areas such as Neural Net Training, Rendering and Simulation.
In these applications, connectivity between compute hardware as well as storage play a major role in overall system performance. CoreWeave provides highly optimized IP-over-Ethernet connectivity across all GPUs and an industry-leading, non-blocking InfiniBand fabric for our top-of-the-line A100 NVLINK GPU fleet.
HPC over IP / Ethernet
CoreWeave Cloud Native Networking (CCNN) and Layer 2 VPC (L2VPC) are both optimized for high throughput and low latency.
The CoreWeave Ethernet fabrics employ a cut-through design with sub-microsecond switching. Many HPC workloads perform well over vanilla networking, with no further optimizations or configuration necessary. Many customers successfully train and fine-tune Large Language Models (LLMs) using the standard Cloud Native Networking to underpin their distributed training, running NVIDIA NCCL over IP transport. NCCL is supported across all CoreWeave GPUs.
Read a case study about training a 20 Billion parameter NLP model on 96 NVIDIA A40 GPUs with Ethernet interconnect.
HPC over RDMA / InfiniBand
For certain workloads, such as training massive language models of over 100 billion parameters over hundreds or thousands of GPUs, the fastest and lowest latency interconnect is required.
CoreWeave has partnered with NVIDIA in its design of interconnect for A100 HGX training clusters. All CoreWeave A100 NVLINK GPUs offer GPUDirect RDMA over InfiniBand, in addition to standard IP/Ethernet networking.
GPUDirect allows GPUs to communicate directly with other GPUs across an InfiniBand fabric, without passing through the host system CPU and operating system kernel, which significantly lowers synchronization latency.
 (1) (2) (2).4bec5d2.1200.png)
Node Topology
 (2).59cf7d4.1200.png)
The A100 HGX nodes are each equipped with 8x NVIDIA A100 80GB GPUs. These GPUs connect to an NVIDIA NVSWITCH baseboard for 600GB/s of intra-node interconnect. The GPUs are also connected to NVIDIA Mellanox CX-6 InfinBand HCAs for connection to the inter-node InfiniBand fabric. Each compute node is uplinked with 1.6Tbps of effective bandwidth with SHARP optimizations.
Fabric Topology
The InfiniBand fabric itself consists exclusively of NVIDIA Quantum HDR and NDR InfiniBand Switches. Network topology is carefully designed to match the highest standards found in NVIDIA DGX clusters. The network is laid out in a non-blocking, Fat Tree architecture. In addition to no oversubscribed links, the topology is rail-optimized allowing for even further latency optimizations in all-reduce style operations.
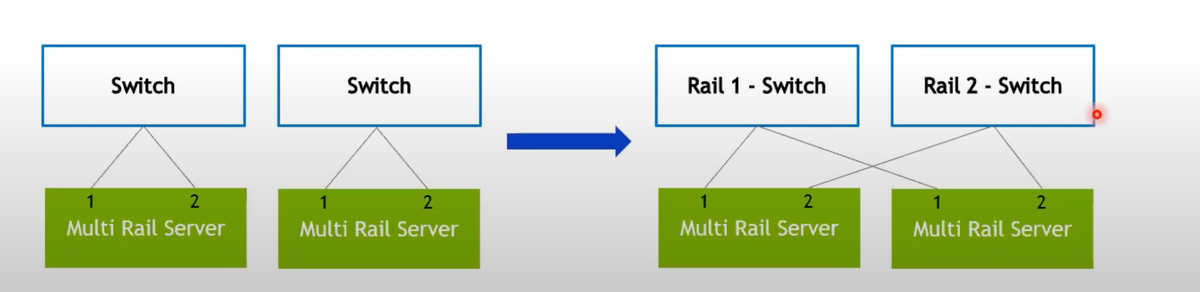
Fabrics provide hundreds of terabits of aggregate bandwidth. Each high-performance link is carefully monitored and optimized using best of breed NVIDIA tooling.
 (1) (1) (3).c85f5b1.1200.png)
NVIDIA Mellanox SHARP
Traditionally, communication requirements scale proportionally with number of nodes in a HPC cluster. NVIDIA® Mellanox® Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) moves collection operations from individual nodes into the network. This allows for a flat scaling curve and significantly improved effective interconnect bandwidth.
By processing data as it traverses the network, NVIDIA Quantum switches eliminate the need to send data multiple times between server endpoints. They also support the aggregation of large data vectors at wire speed, which are crucial for machine learning applications. CoreWeave's InfiniBand topology is fully SHARP compliant, and all components to leverage SHARP are implemented in the network control-plane, such as Adaptive Routing and Aggregation Managers.
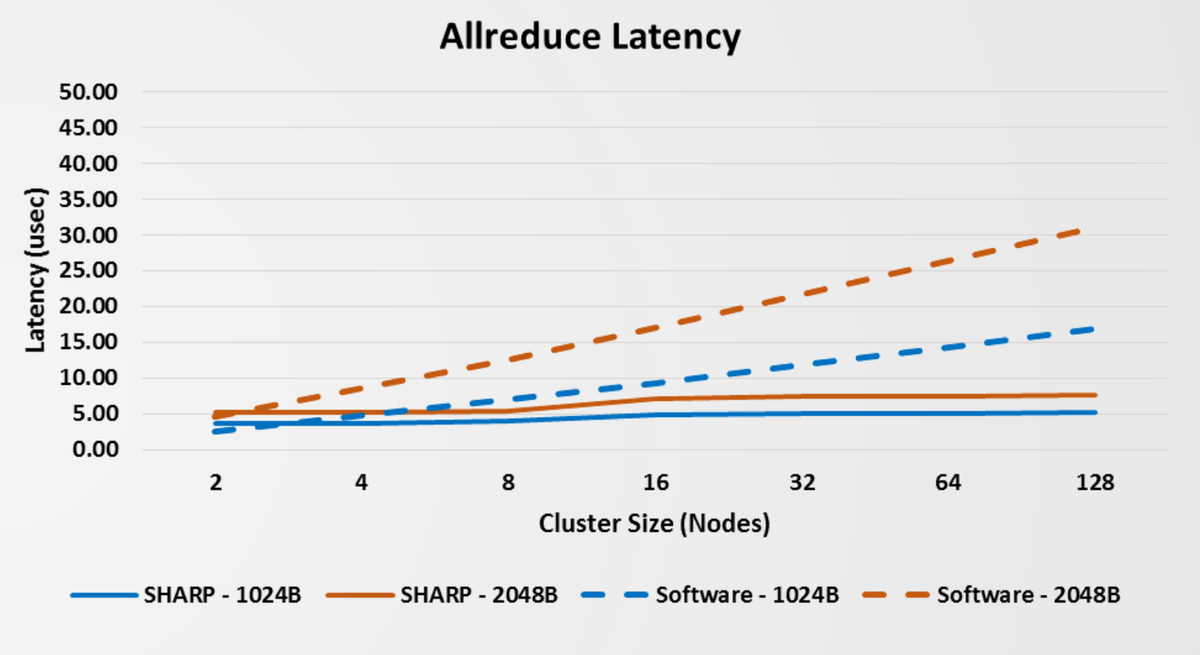
SHARP effectively doubles the performance of a compliant InfiniBand network compared to a network with similar specifications without in-network computing such as RDMA over Converged Ethernet (RoCE).
Bare Metal Environment
Training, Rendering and Simulation workloads execute in CoreWeave's bare metal container environment. GPU Drivers, NIC drivers and InfiniBand configuration are handled on the host node without any customer interaction required.
Customers schedule workloads via Kubernetes, potentially leveraging distributed task managers such as Determined.ai, MPI Operator and Argo Workflows, all of which are available out of the box on CoreWeave Cloud.
A repository of template Docker images and Dockerfiles is available for customers to use as a base for their own images. These base images include all libraries necessary to optimally leverage NCCL with SHARP.
While Kubernetes is the preferred method for job scheduling, other schedulers, such as SLURM, may be accommodated for long-term, reserved-instance customers.