

Tutorial outline
This long-form tutorial comprises the pages underneath this section. Follow them in the order they are numbered, because each page builds on the resources deployed in the previous one. In this tutorial, you:- Set up infrastructure dependencies.
- Configure monitoring and observability.
- Deploy vLLM inference service.
- Monitor performance and test autoscaling.
What you'll need
Before you start, you must have:
- A working CKS cluster with GPU and CPU Nodes.
- The following tools installed on your local machine:
- Access to Hugging Face models (with tokens if required for gated models).
What you'll use
In this tutorial, you’ll use the following tools and services:
- vLLM: High-performance LLM inference engine.
- Traefik: Ingress controller for external traffic routing.
- cert-manager: Automatic TLS certificate management.
- Prometheus and Grafana: Monitoring and observability stack.
- KEDA: Kubernetes Event-driven Autoscaling.
- CoreWeave Helm charts: Preconfigured deployment templates.
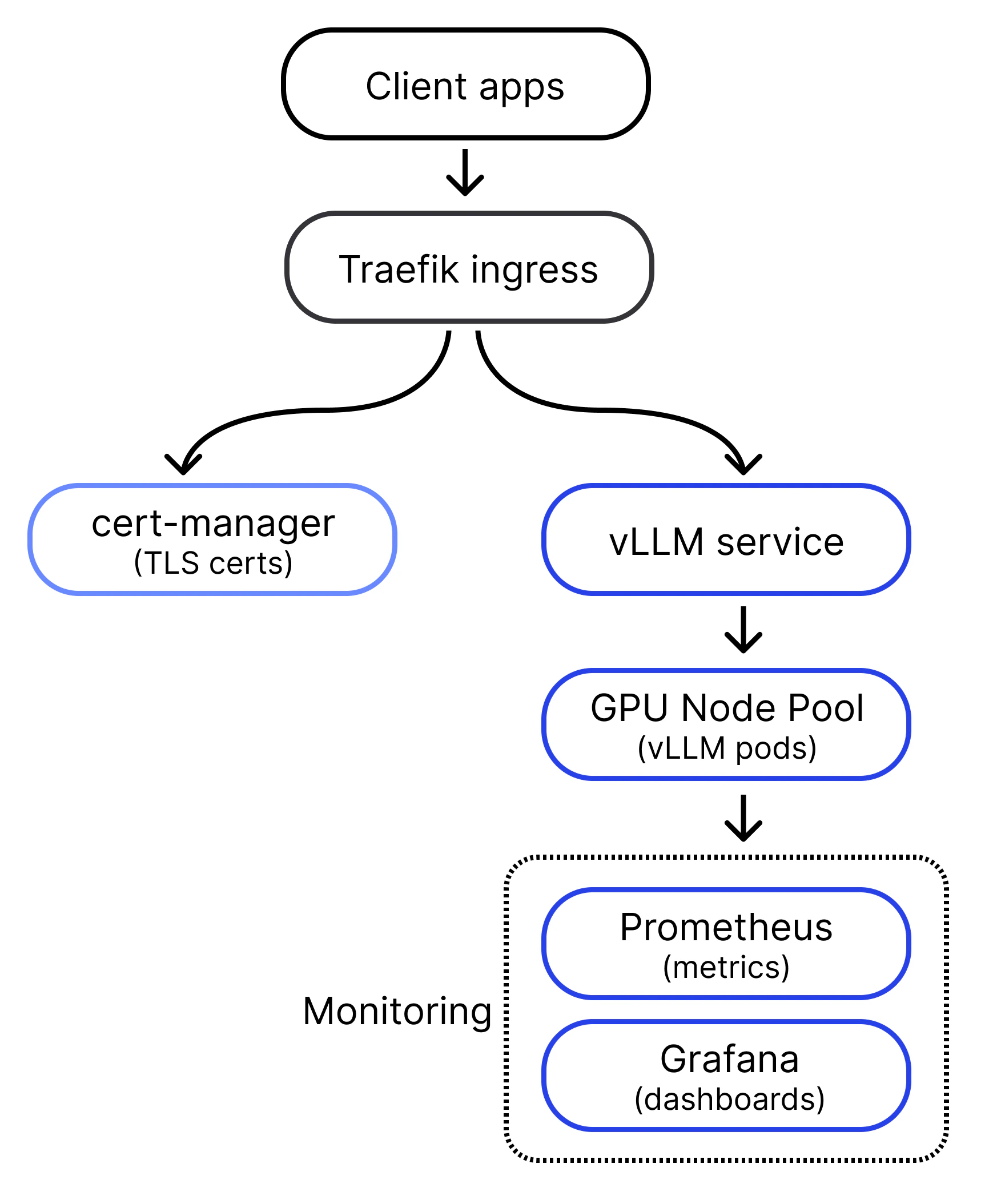
Architecture overview
Before you start the procedures, it helps to understand how the pieces fit together. The complete vLLM inference solution consists of several components working together:- vLLM service: The main inference engine that runs your language model.
- Traefik ingress: Handles external traffic routing and TLS termination.
- cert-manager: Manages automatic SSL certificate generation and renewal.
- Prometheus: Collects metrics from vLLM and other components.
- Grafana: Provides dashboards that monitor inference performance.
- KEDA: Enables autoscaling based on custom metrics like request queue depth.
Prerequisites
Before you begin the tutorial, verify that your environment meets the following requirements. Each check confirms a capability that later steps depend on.-
You can access your cluster using
kubectl. For example, run the following command:You should see something similar to the following: -
Your cluster has at least one CPU Node.
For example, run the following command:
You should see something similar to the following:
-
Your CKS cluster must have GPU Nodes with at least 16 GB of GPU memory, which is required by the Llama 3.1 8B Instruct model used in this tutorial.
For example, run the following command:
You should see something similar to the following:Under
VRAM, the number should be 16 or greater.
Additional resources and information
You don’t need to install the following tools yourself. They are preinstalled on CKS worker Nodes:- Docker: Container runtime for running vLLM inference Pods.
- NVIDIA drivers: GPU drivers for CUDA acceleration.
- CoreWeave CSI drivers: Storage drivers for persistent volumes.
- CoreWeave CNI: Network plugins for Pod communication.