Day 2+
An automated lifecycle management and validation platform
CoreWeave has developed advanced Day 2+ systems that enhance the reliability and performance of our infrastructure. Through automated validation, continuous monitoring, and rapid remediation, we ensure that every component—from compute Nodes to InfiniBand fabrics—operates efficiently from initial deployment through production.
How it works
Our systems perform ongoing health checks and fabric diagnostics, enabling faster cluster provisioning and early fault detection. This proactive approach keeps our infrastructure running at peak efficiency.
To ensure your workloads remain reliable, CoreWeave leverages a combination of active testing and passive monitoring to identify and resolve issues—often before they impact your workloads.
Active health checks
To ensure Node reliability, CoreWeave runs periodic HPC Verification tests that use all GPUs on a Node for approximately 20 minutes. These tests execute once per hour and are visible in Grafana dashboards, where you'll see a spike in GPU SM Utilization, CPU Utilization, and GPU Memory Utilization metrics.
The GPU SM Utilization metric indicates how actively the GPU's compute cores (streaming multiprocessors) are being used. High values reflect the compute-intensive activity during the test window. These spikes have a consistent pattern across all GPUs on each Node, as shown in the example below.
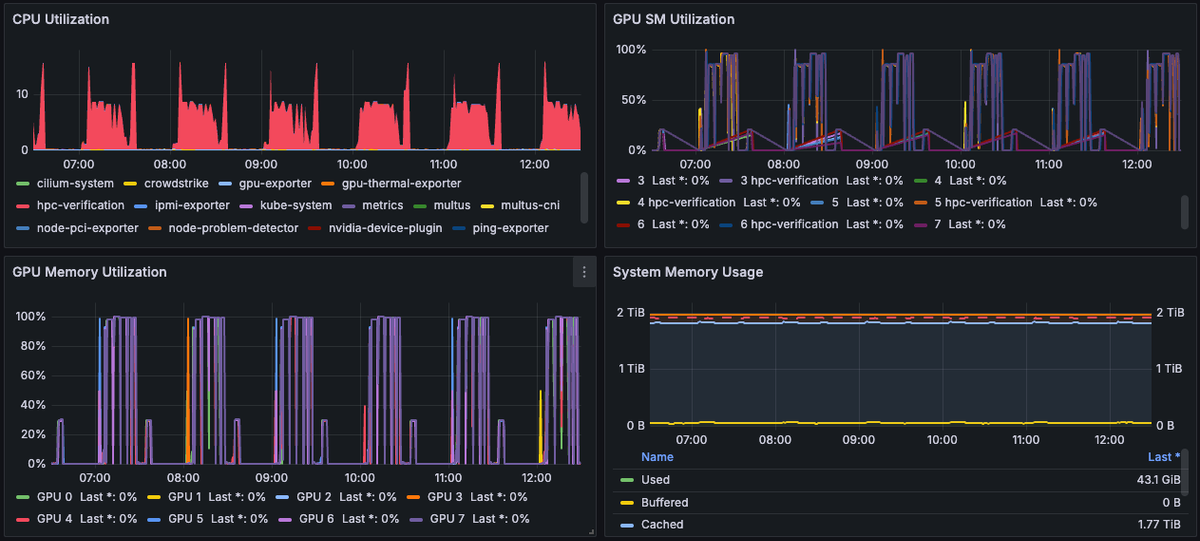
Importantly, these tests only run on idle Nodes, carry a low Kubernetes scheduling priority, and are fully preemptible. If a customer workload is scheduled or already running on a Node, the test will not start—or will be immediately stopped—ensuring zero impact to any jobs. These diagnostic routines validate Node performance under load while remaining completely transparent to your workloads.
Some open-source schedulers, like Volcano, may not support automatic eviction of our verification tests. If you're using a custom scheduler and have questions about active health check behavior, please contact CoreWeave Support.
Passive monitoring
When workloads are active, we collect and analyze both in-band and out-of-band telemetry. We also monitor logs to detect anomalies. When issues arise, we trigger automated remediation through Node lifecycle events.
Automated InfiniBand validation
We test the InfiniBand fabric multiple times daily. Any deviations from the intended topology raise automatic tickets for data center technicians.
Trend analysis
Historical test data is used to identify patterns, predict failures, and fine-tune performance over time.
Manual InfiniBand testing
Our network team also performs weekly manual inspections to catch rare or complex issues that automation might miss.
Why this matters
With CoreWeave's automated infrastructure lifecycle:
- Node provisioning is faster
- System health issues are caught earlier
- Performance bottlenecks are minimized
These systems keep CKS clusters reliable and high-performing—two essential requirements for AI workloads.