Cost and Usage Monitoring
Learn how to monitor your CoreWeave usage and estimate costs
Understanding your resource consumption is crucial for managing costs and optimizing performance. This guide explains the key metrics available in Grafana for monitoring your compute, storage, and networking usage on CoreWeave Cloud and provides practical examples of how to use them.
Prerequisites
The metrics are available in the Explore section of the Grafana instance hosted by CoreWeave. To access Grafana, you need to be logged into the CoreWeave Cloud Console and a member of the admin, metrics, or write groups.
Follow these steps to get started:
- Log into the CoreWeave Cloud Console.
- Click Grafana in the left-hand navigation menu.
- Within Grafana, select Explore in the left-hand navigation menu.
Key usage metrics
These metrics provide insight into resource consumption. You can query them directly to create time-series graphs or compute aggregations.
Compute usage
Metric billing:instance:total
This metric provides the number of Nodes (instances) running in the selected clusters. Units are in instances.
These labels are available for filtering and grouping:
| Label | Description | Example | Notes |
|---|---|---|---|
cluster | The name of the CKS cluster | my-cluster | See clusters in Cloud Console. |
cluster_org | The Organization ID | abc123 | Queries are automatically scoped to the organization. |
label_node_kubernetes_io_instance_type | The Node instance type | gb200-4x | See the list of instance types. |
node_pool_name | The Node Pool that the Nodes belong to within the CKS cluster | h100-training | See Node Pools in Cloud Console. |
region | The Region where the Nodes are located | US-EAST-02 | See the list of Regions. |
zone | The Zone where the Nodes are located | US-EAST-02A | See the list of Availability Zones. |
Clusters created before July 7, 2025 should filter out the cpu-control-plane Node Pool with the following query when estimating billable compute usage:
node_pool_name != "cpu-control-plane"
These Nodes are not billable. Clusters created after this date do not have a cpu-control-plane Node Pool.
Storage usage
Metric billing:object_storage_used_bytes:total
This metric provides the amount of data stored in CoreWeave AI Object Storage. Units are in bytes.
The following labels are available for filtering and grouping:
| Label | Description | Example | Notes |
|---|---|---|---|
billing_label | The product tier | caios-high-perf | Use this label for filtering or aggregating by product tier. |
bucket_name | The bucket name | my-bucket | See buckets in Cloud Console. |
cluster_org | Your Organization ID | abc123 | Queries are automatically scoped to the organization. |
storage_class | The storage class name | STANDARD | This label exists for S3 compatibility and maps to billing_label, which is preferred for queries. |
region | The Region where the storage is located | US-EAST-02 | See the list of Regions. |
zone | The Zone where the storage is located | US-EAST-02A | See the list of Availability Zones. |
The underlying data for this metric is only guaranteed to be updated once per hour.
Metric billing_resource_usage_storage
This metric provides the size of storage volumes provisioned for CKS clusters. Units are in bytes.
The following labels are available for filtering and grouping:
| Label | Description | Example | Notes |
|---|---|---|---|
cluster | The name of the CKS cluster the storage volumes belong to | my-cluster | See clusters in Cloud Console. |
cluster_org | Your Organization ID | abc123 | Queries are automatically scoped to the organization. |
storage_class | The storage class name | shared-vast | |
namespace | The CKS cluster namespace the storage volumes belong to | my-namespace |
Networking usage
Metric billing_ip_address
This metric provides the number of public IP addresses provisioned in your CKS clusters. These are typically associated with LoadBalancer Kubernetes services. Units are in public IP addresses.
The following labels are available for filtering and grouping:
| Label | Description | Example | Notes |
|---|---|---|---|
cluster | The name of the CKS cluster the IP addresses belong to | my-cluster | See clusters in Cloud Console. |
cluster_org | Your Organization ID | abc123 | Queries are automatically scoped to the organization. |
namespace | The CKS cluster namespace the IP addresses belong to | my-namespace |
Practical monitoring examples
Here are common scenarios where you can use Grafana's metrics to monitor your usage and costs.
Exploring usage trends over time
Visualizing usage trends helps you spot patterns, detect anomalies, and assess the impact of changes. Long-term trends can support forecasting, while short-term trends can reveal issues.
To explore usage trends, follow these steps:
- Navigate to Grafana's Explore section. (See Prerequisites)
- Select a desired Time range using the picker in the top right.
- Enter your query in the query editor.

- Ensure the query Type in the Options section is set to Range or Both.
- Click Run query (or press Shift+Enter).
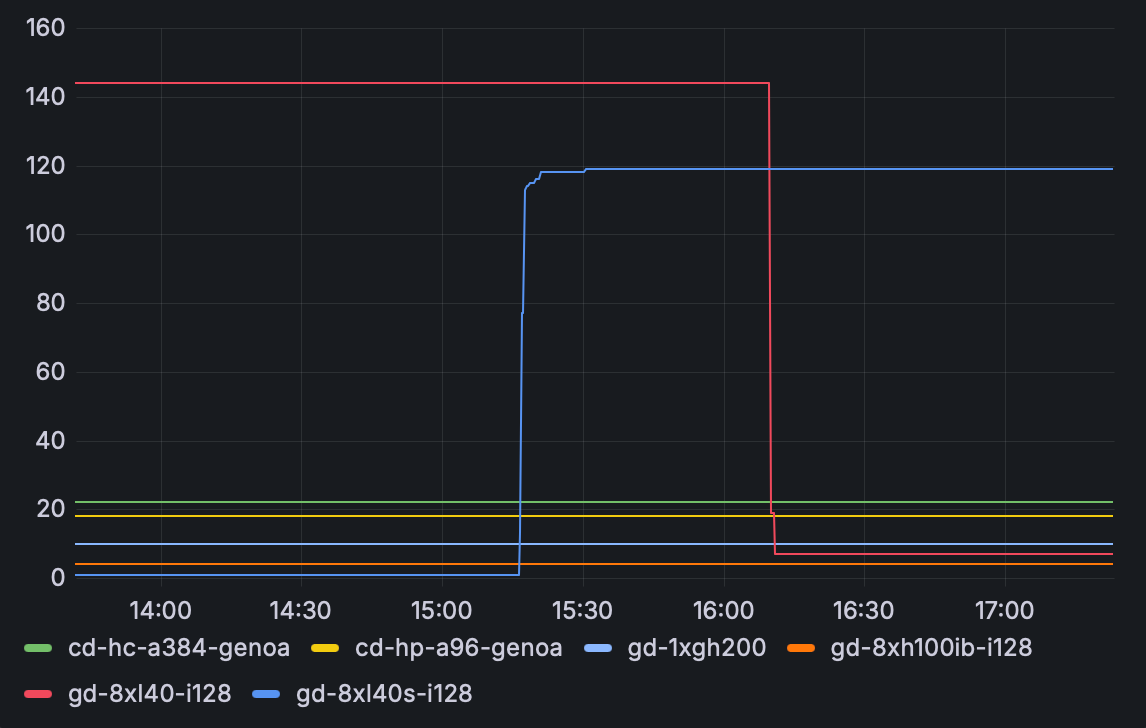
Example: Billable GPU and CPU instances grouped by type
Use this query to find the count of billable instances, grouped by their type.
sum by (label_node_kubernetes_io_instance_type) (billing:instance:total{node_pool_name!="cpu-control-plane"})
The graph displays the instance count over the specified time range.
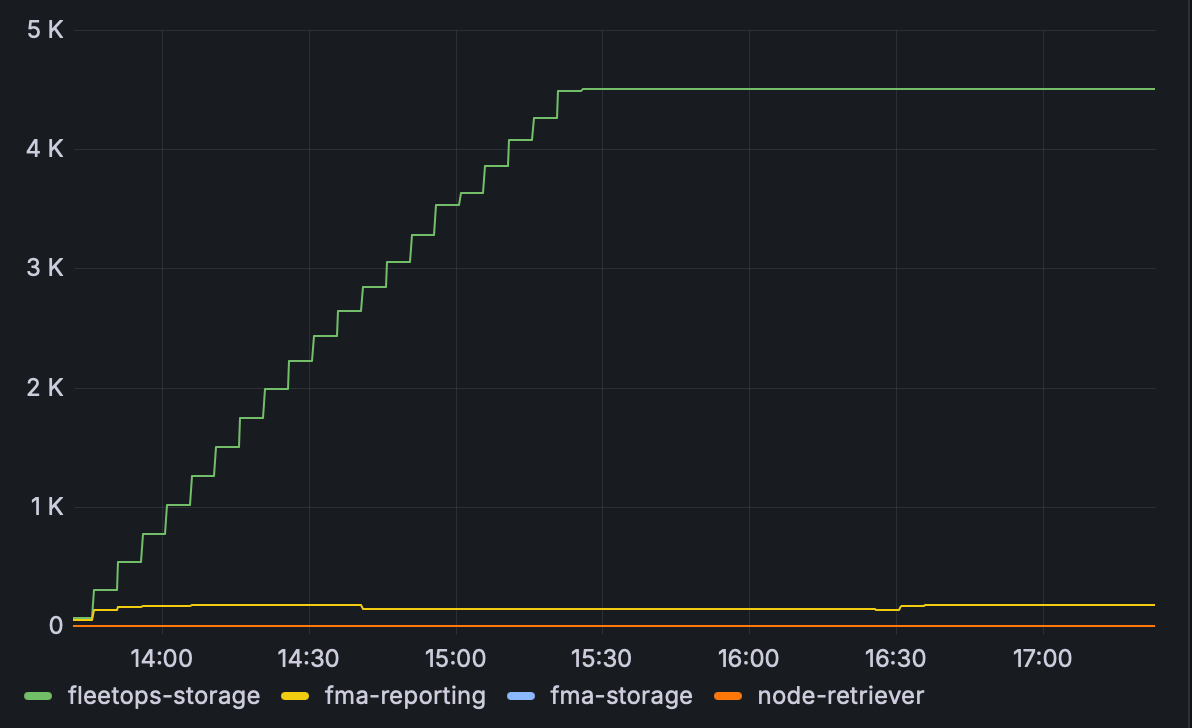
Example: Billable AI Object Storage grouped by bucket in GiB
Use this query to find the total storage used in CoreWeave AI Object Storage, grouped by bucket name and converted to GiB.
sum by (bucket_name) (billing:object_storage_used_bytes:total) / 1024^3
The graph displays the total storage used in each bucket over the specified time range.
Example: Distributed File Storage in GiB
Use this query to find the total provisioned size of storage volumes that use the shared-vast storage class, converted to GiB.
sum(billing_resource_usage_storage{storageclass="shared-vast"}) / 1024^3
The graph displays the total provisioned size of storage volumes over the specified time range.

Estimating total On-Demand costs for a time period
While Reserved instances provide guaranteed access at a fixed rate, any usage beyond Reservations is metered as On-Demand. You can estimate your On-Demand costs using Grafana.
This provides an estimate based on standard On-Demand rates and your real-time usage metrics. Actual billed amounts may vary based on contracts, discounts, taxes, and billing cycle specifics.
Example: Month-to-date On-Demand estimate excluding Reservation
Assume the following scenario:
- 25 Reserved H200 Nodes (
gd-8xh200ib-i128) - L40S Nodes run On-Demand (
gd-8xl40s-i128) - General Purpose AMD Genoa run On-Demand (
cd-gp-a192-genoa) - CoreWeave AI Object Storage, Distributed Filesystem Storage, and Public IP addresses are in use
- No additional discounts on On-Demand usage
To estimate the total On-Demand costs for the month-to-date, follow these steps.
-
Navigate to Grafana's Explore section. (See Prerequisites)
-
Select This month so far in the time range picker.
-
Enter the following query, replacing the instance types and prices with your specific details and current On-Demand rates:
# --- ESTIMATED ON-DEMAND COST QUERY ---# Note: Prices used are examples. Replace with current On-Demand rates.sum_over_time(sum(# H200 On-Demand: Count above Reservation (25), clamp at 0, multiply by hourly rate ($50.44)clamp_min(sum(billing:instance:total{label_node_kubernetes_io_instance_type="gd-8xh200ib-i128"}) - 25, # Subtract Reserved count0) * 50.44+# L40S On-Demand: Count all, multiply by hourly rate ($18.00)sum(billing:instance:total{label_node_kubernetes_io_instance_type="gd-8xl40s-i128"}) * 18.00+# Genoa On-Demand: Count all (excluding Control Plane), multiply by hourly rate ($7.78)sum(billing:instance:total{label_node_kubernetes_io_instance_type="cd-gp-a192-genoa",node_pool_name!="cpu-control-plane" # Exclude non-billable}) * 7.78+# AI Object Storage On-Demand: Sum bytes, convert GiB/month rate ($0.000151/GiB/hr)sum(billing:object_storage_used_bytes:total) * 0.000151 / 1024^3+# Shared-Vast Storage On-Demand: Sum bytes, convert GiB/month rate ($0.000096/GiB/hr)sum(billing_resource_usage_storage{storageclass="shared-vast"}) * 0.000096 / 1024^3+# Public IPs On-Demand: Count IPs, multiply by hourly rate ($0.0055)sum(billing_ip_address) * 0.0055)[$__range:30s] # Use appropriate range vector and step for accuracy) / 120 # Adjust divisor based on range vector step (for 30s step over an hour, divide by 120) -
Ensure the query Type in the Options section is set to Instant.
-
Click Run query (or press Shift+Enter).
The resulting value is an estimate of the total dollar amount for your On-Demand usage during the selected time period (month-to-date in this example).
About range vectors and step size
In this query, $__range:30s sets the time range and the step size for the data. The 30s step means the query evaluates data points every 30 seconds across the selected time range in Grafana.
The query uses a divisor of 120 to normalize the total across all 30-second intervals in a 1-hour range. This converts the result into an average hourly rate. For example, there are 120 intervals in one hour when using a 30-second step (60 minutes * 2).
If you change the step size, update the divisor to match. For example:
- Use
60for a1mstep size - Use
240for a15sstep size
Adjusting the divisor ensures the result accurately reflects the average rate over time.
Assessing GPU utilization
Monitoring GPU utilization helps determine if your GPU resources are being used effectively. High utilization might indicate a need for more capacity or Reservations, while low utilization could suggest opportunities for scaling down or consolidating workloads.
Example: Average H100 GPU utilization (including SUNK and non-SUNK workloads)
This query calculates the average utilization percentage for H100 GPUs over the selected time range, considering both GPUs allocated by SUNK jobs and those used by other workloads (excluding specific verification namespaces).
To assess the average GPU utilization for H100 GPUs, follow these steps:
-
Navigate to Grafana's Explore section. (See Prerequisites)
-
Select your desired Time range.
-
Enter the following query:
# --- AVERAGE H100 GPU UTILIZATION (%) ---avg_over_time((# Sum GPUs allocated by SUNK jobs for H100 modelsum(sunk:job_gpus_allocated:total{label_gpu_nvidia_com_model="H100_NVLINK_80GB"})+# Sum GPUs used by non-SUNK workloads for H100 model (excluding hpc.verification)sum(billing_gpu{label_gpu_nvidia_com_model="H100_NVLINK_80GB",namespace!~".*hpc.verification" # Exclude hpc.verification namespace})/ # Divide by total available H100 GPUs(# Sum H100 instances (8 GPUs per instance)sum(billing:instance:total{label_node_kubernetes_io_instance_type="gd-8xh100ib-i128"}) * 8 # Multiply by GPUs per node))[$__range] # Calculate over the selected time range) * 100 # Convert ratio to percentage -
Ensure the query Type in the Options section is set to Instant.
-
Click Run query (or press Shift+Enter).
The result represents the average percentage utilization of your H100 Nodes over the selected period. Adjust the label_node_kubernetes_io_instance_type, label_gpu_nvidia_com_model, and GPUs-per-node multiplier (e.g., * 8) according to the specific instance types you are analyzing.