Fine-Tune GPT-NeoX 20B with Determined AI
Learn how to fine-tune a GPT-NeoX 20B parameter model on CoreWeave Cloud
GPT-NeoX is a 20B parameter autoregressive model trained on the Pile dataset.
It generates text based on context or unconditionally for use cases such as story generation, chat bots, summarization, and so on.
Learn more in the GPT-NeoX-20B: An Open-Source Autoregressive Language Model whitepaper, and view the GPT-NeoX source code on GitHub.
This model is trained on CoreWeave infrastructure and the weights are made available via a permissive license. Based on your requirements and use case, this model is capable of high quality text generation. Many customers have seen drastically improved results by finetuning the model with data specific to their use case.
This guide will use the DeterminedAI MLOps platform to run distributed finetuning jobs on the model.
Prerequisites
This guide assumes that the following are completed in advance.
- You have set up your CoreWeave Kubernetes environment locally
gitis locally installed- Determined AI is installed in your namespace, including installation prerequisites:
- FileBrowser is installed
- A shared filesystem volume with an easily-recognizable name, such as
finetune-gpt-neox, is created - An Object Storage bucket with an easily-recognizable name, such as
model-checkpoints, is created
The values used for this demo's shared filesystem volume are as follows:
| Field name | Demo value |
|---|---|
| Volume Name | finetune-gpt-neox |
| Region | LAS1 |
| Disk Class | HDD |
| Storage Type | Shared Filesystem |
| Size (Gi) | 1000 |
If needed, it is easy to increase the size of a storage volume later.
Attach the filesystem volume
When installing Determined AI, ensure that the newly-created filesystem volume for this demo is attached. From the bottom of the application configuration screen, click + to attach the finetune-gpt-neox volume.
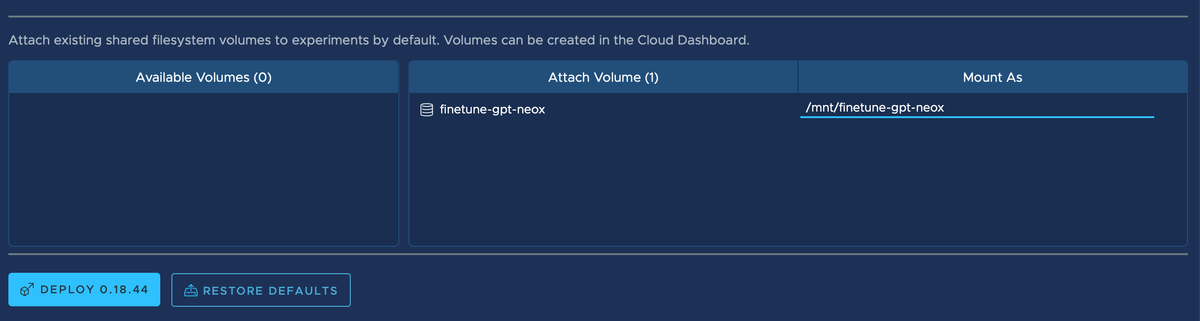
As shown above, for this tutorial we are attaching the finetune-gpt-neox volume to mount path /mnt/finetune-gpt-neox.
Determined Web UI
After deploying the DeterminedAI application, a URL to the Web UI will be provided. Navigate here to use the Determined AI Web UI, which may be used to monitor experiments and to check logs.
 (1) (1).a4d3118.1200.png)
As an example, here is what a live experiment looks like when viewed from the Web UI.
.19e81d4.1200.png)
Navigating to the Logs tab will give you a full output of the experiment's logs:
 (1).01db8fa.1200.png)
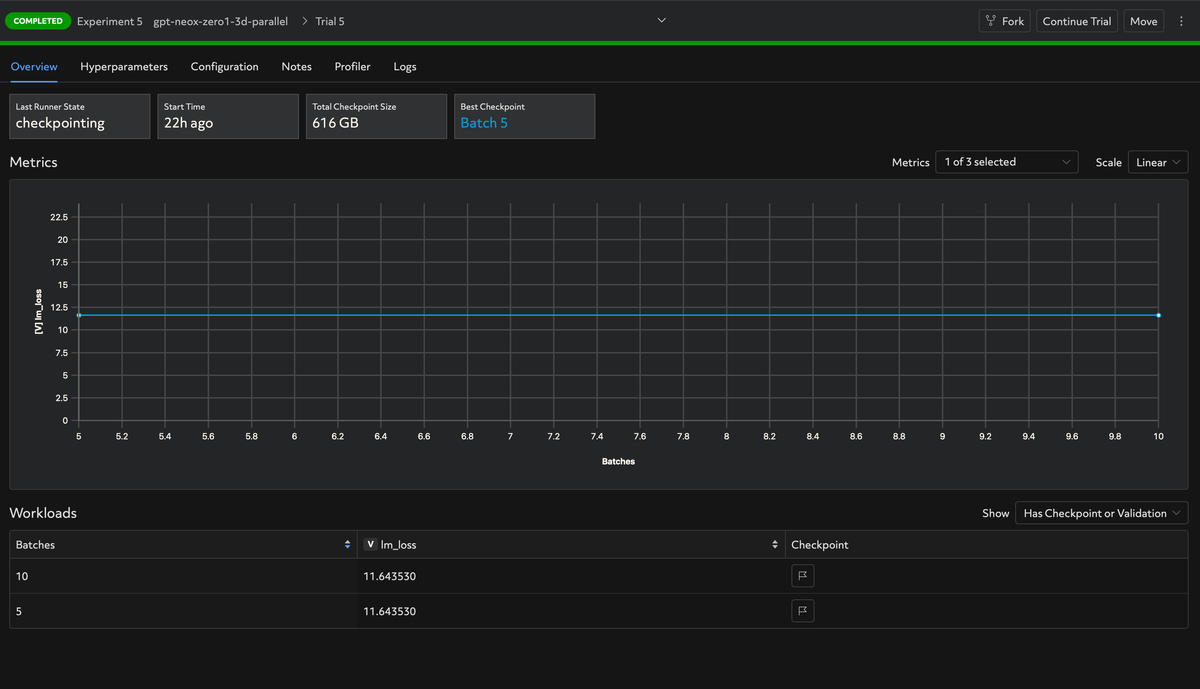
Navigating to Overview will give you access to a metrics visualization of the experiment and checkpoint reference.
 (1).efab51a.1200.png)
Training
Configure your dataset
Run theexport DET_MASTER=...ord1.ingress.coreweave.cloud:80 command, found in the post-installation notes from the DeterminedAI deployment, prior to running the next command.
Clone the GPT-NeoX repository to your CoreWeave Cloud Storage in a terminal:
$det cmd run 'git clone https://github.com/EleutherAI/gpt-neox.git /mnt/finetune-gpt-neox/gpt-neox'
Then, download the Vocab and Merge files to your CoreWeave Cloud Storage in a terminal:
$det cmd run 'wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json-O /mnt/finetune-gpt-neox/gpt2-vocab.json'$det cmd run 'wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt-O /mnt/finetune-gpt-neox/gpt2-merges.txt'$det cmd run 'wget https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/20B_tokenizer.json-O /mnt/finetune-gpt-neox/20B_tokenizer.json'
Dataset Format
Datasets for GPT-NeoX should be one large document in JSONL format. To prepare your own dataset for training with custom data, format it as one large JSONL-formatted file, where each item in the list of dictionaries is a separate document.
The document text should be grouped under one JSON key, i.e "text".
Example
{"text": "We have received the water well survey for the N. Crawar site. The Crane \nCounty Water District owns 11 water wells within a one mile radius of the \nsite. The nearest well is located about 1000 feet east of the site. It \nappears that all of the wells are completed into the uppermost aquifer and, \nin general, are screened from 50' bgs to total depth at about 140' bgs. The \nshallow water table at the site and in the nearby wells is at about 50' bgs. \nThe groundwater flow direction at the site has consistently been toward due \nsouth. There are no water supply wells within one mile due south of the site. \nThere are two monitor wells at the east side of the site which have always \nproduced clean samples. The remediation system for this site should be \noperational by April 1, 2001. We will also have more current groundwater \nsampling information for the site within the next few weeks.", "meta": {}}{"text": "Roger-\nWe will require off-site access for the installation of 10 remediation wells \nat the North Crawar facility (formerly owned by TW but now owned by Duke). I \nwill drop off in your office a site diagram that indicates the location of \nthe wells relative to the facility and the existing wells. I believe that the \nadjacent property owner had been contacted prior to well installations in \nAugust 1997, but I am not familiar with the details of the access agreement \nor even who within ET&S made the arrangements. We are shooting for \nearly-October for the well installations. We may also want to address \ncontinued access to the wells in an agreement with the landowner (a 5-10 year \nterm should be sufficient). Give me a call at x67327 if you have any \nquestions.\nThanks,\nGeorge", "meta": {}}{"text": "Larry, the attached file contains a scanned image of a story that was \npublished in The Monahans News, a weekly paper, on Thursday, April 20, 2000. \nI've shown the story to Bill, and he suggested that you let Rich Jolly know \nabout the story.\n\nThanks, George\n\n\n---------------------- Forwarded by George Robinson/OTS/Enron on 04/24/2000 \n03:29 PM ---------------------------\n\n04/24/2000 03:21 PM\nMichelle Muniz\nMichelle Muniz\nMichelle Muniz\n04/24/2000 03:21 PM\n04/24/2000 03:21 PM\nTo: George Robinson/OTS/Enron@ENRON\ncc: \n\nSubject: Newspaper\n\nI hope this works. MM", "meta": {}}
There are several standard datasets that you can leverage for testing.
Pre-processing your dataset
Upload your data as a single JSONL file called data.jsonl to filebrowser under finetune-gpt-neox:
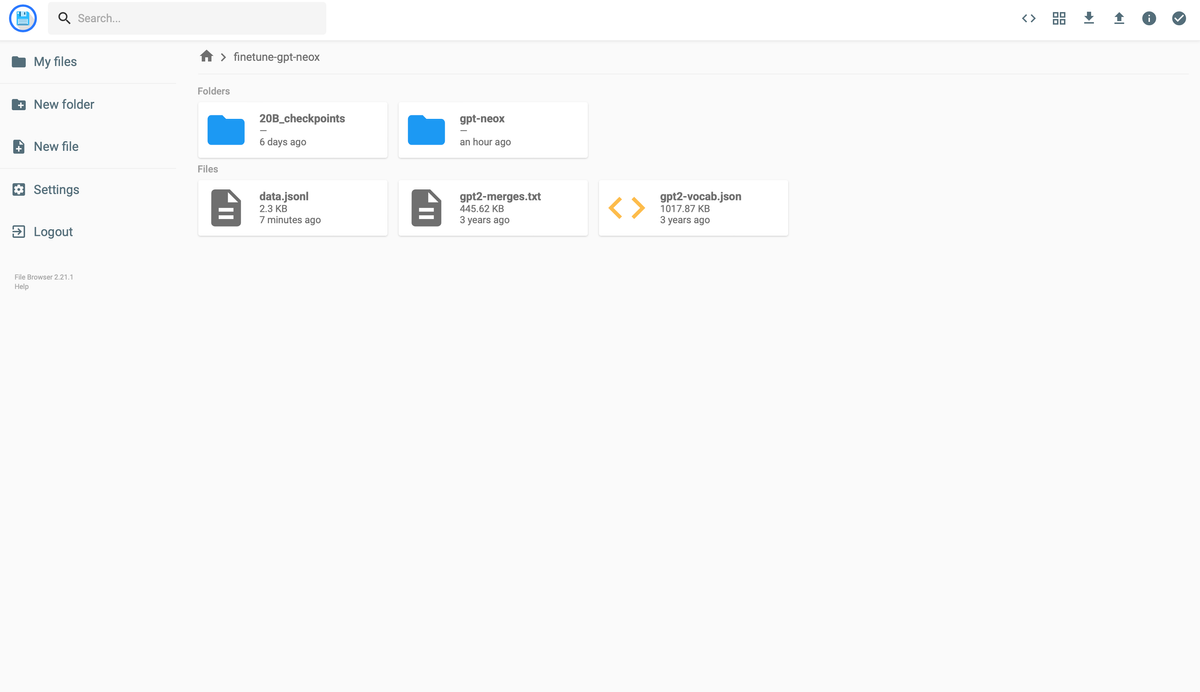
Using the FileBrowser app, create a new folder called gpt_finetune under the finetune-gpt-neox folder.
 (3) (1).3ffe208.1200.png)
You can now pre-tokenize your data using tools/preprocess_data.py. The arguments for this utility are listed below.
preprocess_data.py Arguments
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]optional arguments:-h, --help show this help message and exitinput data:--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]space separate listed of keys to extract from jsonl. Defa--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.tokenizer:--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}What type of tokenizer to use.--vocab-file VOCAB_FILEPath to the vocab file--merge-file MERGE_FILEPath to the BPE merge file (if necessary).--append-eod Append an <eod> token to the end of a document.--ftfy Use ftfy to clean textoutput data:--output-prefix OUTPUT_PREFIXPath to binary output file without suffix--dataset-impl {lazy,cached,mmap}Dataset implementation to use. Default: mmapruntime:--workers WORKERS Number of worker processes to launch--log-interval LOG_INTERVALInterval between progress updates
The command to tokenize your data and output it to gpt_finetune is below:
$python tools/preprocess_data.py \--input /mnt/finetune-gpt-neox/data.jsonl \--output-prefix /mnt/gpt_finetune/mydataset \--vocab /mnt/finetune-gpt-neox/20B_tokenizer.json \--tokenizer-type HFTokenizer
Run this command to pre-process and tokenize your data:
$det cmd run 'apt-get -y install libopenmpi-dev;pip install -r /mnt/finetune-gpt-neox/gpt-neox/requirements/requirements.txt;python tools/preprocess_data.py \--input /mnt/finetune-gpt-neox/data.jsonl \--output-prefix /mnt/gpt_finetune/mydataset \--vocab /mnt/finetune-gpt-neox/20B_tokenizer.json \--tokenizer-type HFTokenizer'
Tokenized data will be saved out to two files:
<data-dir>/<dataset-name>/<dataset-name>_text_document.binand <data-dir>/<dataset-name>/<dataset-name>_text_document.idx.
You will need to add the prefix that both these files share to your training configuration file under the data-path field.
You should see the data here similar to below:
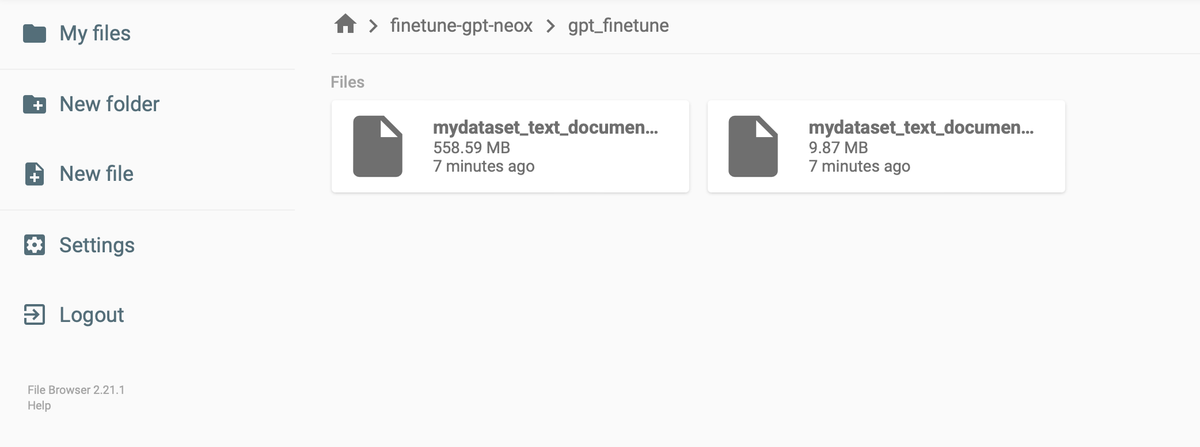
Finetuning
Run theexport DET_MASTER=...ord1.ingress.coreweave.cloud:80 command, found in the post-installation notes from the DeterminedAI deployment, prior to running the next command.
Download the "Slim" weights by running the following commands in a terminal:
$det cmd run 'wget --cut-dirs=5 -nH -r --no-parent --reject "index.html*" https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P /mnt/finetune-gpt-neox/20B_checkpoints'
Ensure that the above command completes executing. Depending on your network bandwidth, downloading weights can take up to an hour or two for 39GB of data. You can monitor the logs of the above command using the logs command:
$det task logs -f <TASK_NAME_FROM_ABOVE>
Download the training examples
DeterminedAI provides training examples on GitHub. Clone the source code for the DeterminedAI from their repository in a terminal in an acccesible path:
$git clone https://github.com/determined-ai/determined.git
The deployment configurations for the experiments and the source code to run the finetuning job are located in the GPT-NeoX example directory under examples/deepspeed/gpt_neox.
EleutherAI provides a lot of useful information on their provided datasets, which may be helpful when configuring datasets and training parameters for tensor and pipeline parallelism for finetuning using GPT-NeoX.
Navigate from the root of the determined.ai source code you cloned previously to the examples/deepspeed/gpt_neox directory.
Review and replace the contents of the original determined-cluster.yml file with the content below to configure the cluster for 96 GPUs in examples/deepspeed/gpt_neox/gpt_neox_config/determined-cluster.yml. You may configure or change any of the optimizer values or training configurations to your needs. It is recommended to use the NeoX source code as reference when doing so.
Click to expand - determined-cluster.yml
{# Tokenizer / checkpoint settings - you will need to change these to the location you have them saved in"vocab-file": "/mnt/finetune-gpt-neox/20B_checkpoints/20B_tokenizer.json",# NOTE: You can make additional directories to load and save checkpoints"load": "/mnt/finetune-gpt-neox/20B_checkpoints","save": "/mnt/finetune-gpt-neox/20B_checkpoints",# NOTE: This is the default dataset. Please change it to your dataset."data-path": "/mnt/finetune-gpt-neox/gpt_finetune/mydataset_text_document",# parallelism settings ( you will want to change these based on your cluster setup, ideally scheduling pipeline stages# across the node boundaries )"pipe-parallel-size": 4,"model-parallel-size": 2,"finetune": true,# model settings"num-layers": 44,"hidden-size": 6144,"num-attention-heads": 64,"seq-length": 2048,"max-position-embeddings": 2048,"norm": "layernorm","pos-emb": "rotary","rotary_pct": 0.25,"no-weight-tying": true,"gpt_j_residual": true,"output_layer_parallelism": "column","scaled-upper-triang-masked-softmax-fusion": true,"bias-gelu-fusion": true,# init methods"init_method": "small_init","output_layer_init_method": "wang_init",# optimizer settings"optimizer": {"type": "Adam","params": {"lr": 0.97e-4,"betas": [0.9, 0.95],"eps": 1.0e-8,}},"min_lr": 0.97e-5,"zero_optimization": {"stage": 1,"allgather_partitions": True,"allgather_bucket_size": 1260000000,"overlap_comm": True,"reduce_scatter": True,"reduce_bucket_size": 1260000000,"contiguous_gradients": True,"cpu_offload": False},# batch / data settings (assuming 96 GPUs)"train_micro_batch_size_per_gpu": 4,"gradient_accumulation_steps": 32,"data-impl": "mmap","split": "995,4,1",# activation checkpointing"checkpoint-activations": true,"checkpoint-num-layers": 1,"partition-activations": false,"synchronize-each-layer": true,# regularization"gradient_clipping": 1.0,"weight-decay": 0.01,"hidden-dropout": 0,"attention-dropout": 0,# precision settings"fp16": {"fp16": true,"enabled": true,"loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 12,"hysteresis": 2,"min_loss_scale": 1},# misc. training settings"train-iters": 150000,"lr-decay-iters": 150000,"distributed-backend": "nccl","lr-decay-style": "cosine","warmup": 0.01,"save-interval": 50,"eval-interval": 100,"eval-iters": 10,# logging"log-interval": 2,"steps_per_print": 2,"wall_clock_breakdown": false,### NEW DATA: ####"tokenizer_type": "HFTokenizer","tensorboard-dir": "./tensorboard","log-dir": "./logs",}
Create the experiment
You will need to be in the examples/deepspeed/gpt_neox directory
Copy the below configuration into a file called finetune-gpt-neox.yml
Click to expand - finetune-gpt-neox.yml
name: gpt-neox-zero1-3d-paralleldebug: falseprofiling:enabled: truebegin_on_batch: 1end_after_batch: 100sync_timings: truehyperparameters:search_world_size: falseconf_dir: /gpt-neox/configsconf_file:- determined_cluster.ymloverwrite_values:pipe_parallel_size: 4wandb_group: nullwandb_team: nulluser_script: nulleval_tasks: nullenvironment:environment_variables:- NCCL_SOCKET_IFNAME=ens,eth,ibforce_pull_image: trueimage:gpu: liamdetermined/gpt-neoxresources:slots_per_trial: 96 # Utilize 96 GPUs for the finetunesearcher:name: singlemetric: lm_losssmaller_is_better: falsemax_length:batches: 100min_validation_period:batches: 50max_restarts: 0entrypoint:- python3- -m- determined.launch.deepspeed- --trial- gpt2_trial:GPT2Trial
Many of the parameters in the above configuration can be changed, such as batches, and slots_per_trail. We use default values of 100 batches to fine-tune on with 50 batches before validation or early stopping, and 96 A40 GPUs .
Run the following command to launch the experiment:
$det experiment create finetune-gpt-neox.yml .
The experiment is now launched! You can see the status of your experiment and monitor logs as well using the Web UI.
You should see an "Active" status for your experiment:

You can visualize and monitor logs:
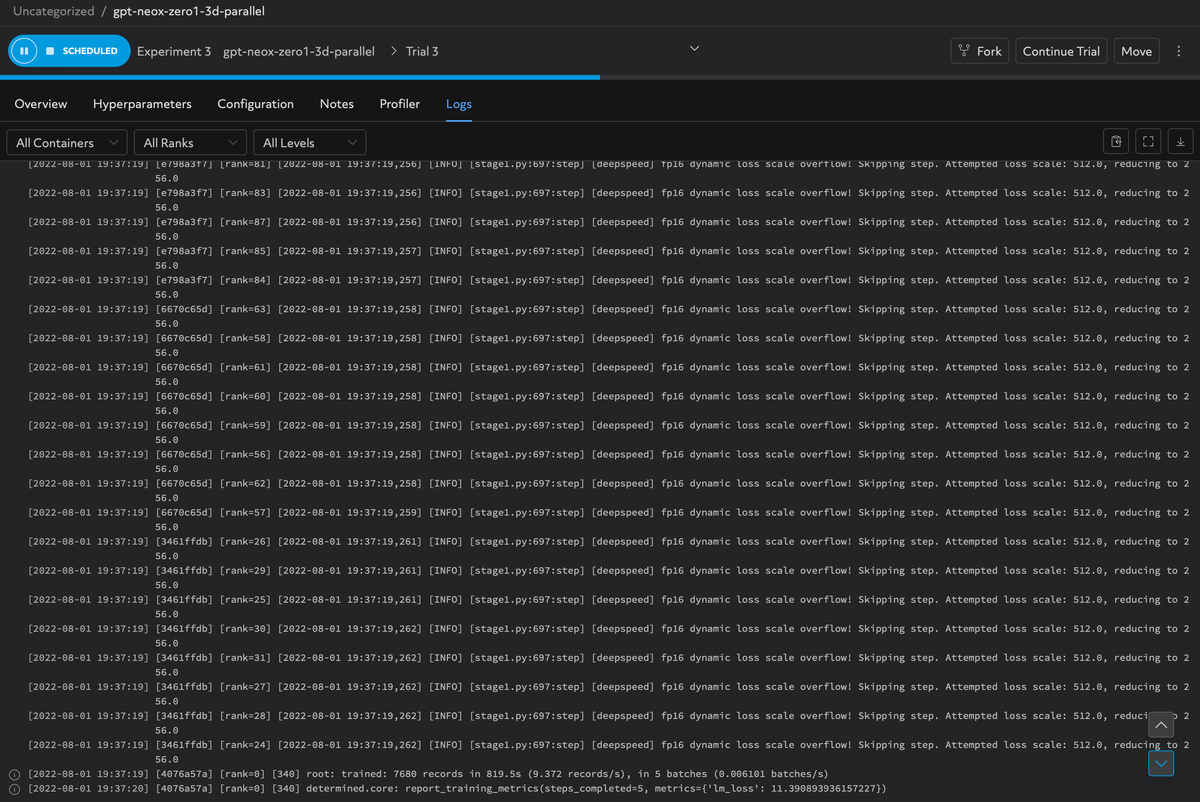
Once training is completed, you will have access to the checkpoint in your S3 bucket for downstream tasks such as inference, transfer learning or model ensembles.
(Optional) Wandb.ai visualization of training graphs
Weights & Biases AI (Wandb.ai) can be installed and configured to visualize training graphs.
Pass in the <WANDB_GROUP> and <WANDB_TEAM> variables to your configuration file.
name: gpt-neox-zero1-3d-paralleldebug: falseprofiling:enabled: truebegin_on_batch: 1end_after_batch: 100sync_timings: truehyperparameters:search_world_size: falseconf_dir: /gpt-neox/configsconf_file:- determined_cluster.ymlwandb_group: <WANDB_GROUP>wandb_team: <WANDB_TEAM>environment:environment_variables:- NCCL_DEBUG=INFO- NCCL_SOCKET_IFNAME=ens,eth,ibforce_pull_image: trueimage:gpu: liamdetermined/gpt-neoxresources:slots_per_trial: 96 # Utilize 96 GPUs for the finetunesearcher:name: singlemetric: lm_losssmaller_is_better: falsemax_length:batches: 100min_validation_period:batches: 50max_restarts: 0entrypoint:- python3- -m- determined.launch.deepspeed- --trial- gpt2_trial:GPT2Trial