FasterTransformer GPT-J and GPT: NeoX 20B
Deploy GPT-J or GPT-NeoX using NVIDIA Triton Inference Server with the FasterTransformer backend
In this example, we'll demonstrate how to deploy EleutherAI GPT-J and GPT-NeoX on NVIDIA Triton Inference Server with the FasterTransformer backend via an InferenceService using an HTTP API to perform Text Generation. This deployment will run on a CoreWeave Cloud NVIDIA RTX A5000 and A6000 GPUs, with Autoscaling and Scale-to-Zero enabled.
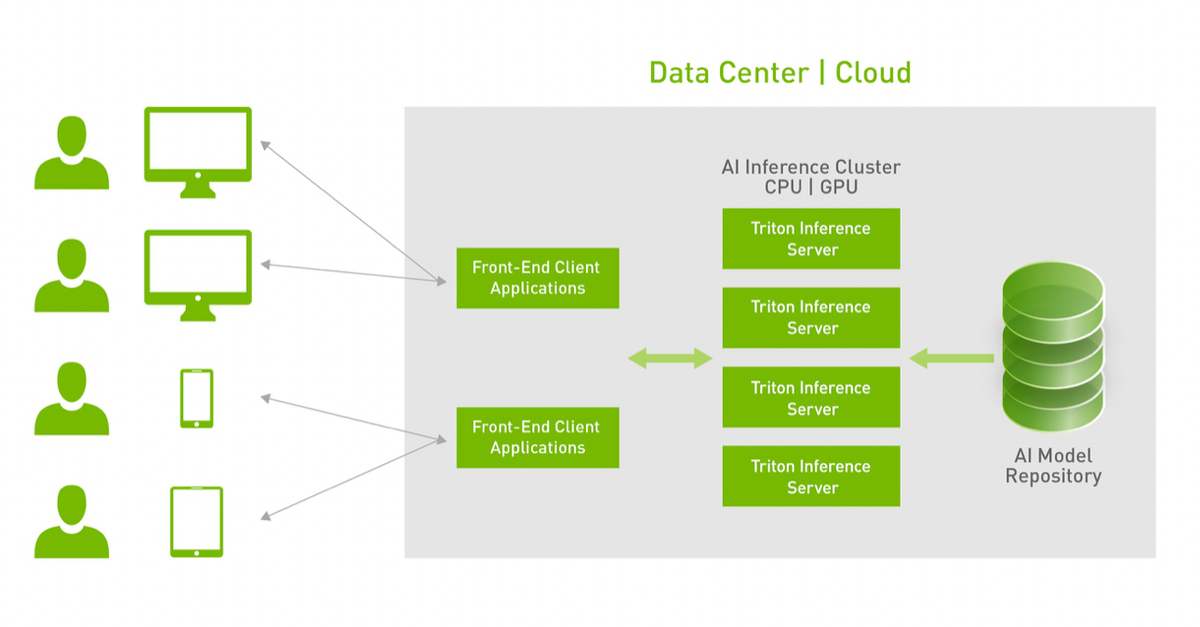
What is FasterTransformer?
In NLP, encoder and decoder are two important components, with the transformer layer becoming a popular architecture for both components. FasterTransformer implements a highly optimized transformer layer for both the encoder and decoder for inference. On Volta, Turing and Ampere GPUs, the computing power of Tensor Cores are used automatically when the precision of the data and weights are FP16.
FasterTransformer is built on top of CUDA, cuBLAS, cuBLASLt and C++. We provide at least one API of the following frameworks: TensorFlow, PyTorch and Triton backend. Users can integrate FasterTransformer into these frameworks directly. For supporting frameworks, we also provide example codes to demonstrate how to use, and show the performance on these frameworks.
FasterTransformer provides up to 40% faster GPT-J inference over an implementation based on vanilla Hugging Face Transformers. FasterTransformer also supports multi-GPU inference for additional speed for handling large models. Streaming of partial completions, token by token, is also supported.
To follow along with this example, view and pull the code on CoreWeave's kubernetes-cloud repository.
Prerequisites
The following tools must be installed prior to running the demo:
- kubectl
- Docker and a Docker Hub account
- An active CoreWeave account (with kubeconfig configured for access credentials)
Overview
No modifications are needed to any of the files to follow along. The general procedure for this example is:
- Build and push the Docker image to a container registry (in this case, Docker Hub).
- Deploy the Kubernetes resources:
- a PVC in which to store the model.
- a Batch Job used to download the model. The model is quite large at roughly 45Gi, and will take around 15-20 minutes to complete the download.
- the CoreWeave InferenceService.
- Perform Text Generation using the model by sending HTTP requests to the InferenceService.
Procedure
Building and pushing the Docker image
Once the example code is cloned to your local machine, enter the build directory. From here, build and push the Docker image to your Docker Hub repository.
Ensure you are logged in to Docker, and make sure the DOCKER_USER environment variable is set:
$docker login$export DOCKER_USER=coreweave
The default Docker tag is latest. We strongly discourage you to use this, as containers are cached on the nodes and in other parts of the CoreWeave stack.
Once you have pushed to a tag, do not push to that tag again. Below, we use simple versioning, using tag 1 for the first iteration of the image, and so on.
From the kubernetes-cloud/online-inference/fastertransformer/build directory, build and push the image:
$docker build -t $DOCKER_USER/fastertransformer-triton:1$docker push $DOCKER_USER/fastertransformer-triton:1
This example assumes a public Docker registry. To use a private registry, an imagePullSecret needs to be defined.
Be sure to configure any usernames in the following examples with your actual Docker Hub username.
Deploying the Kubernetes resources
PVC
Before continuing, you may either point the image: $DOCKER_USER/fastertransformer-triton:1in the following manifests to the image we just built in the previous steps, or you may use the publicly-available image found in the following manifest:
ft-inference-service-gptj.ymlft-inference-service-neox.yml
To create a PVC in which to store the model, navigate to the kubernetes-cloud/online-inference/fastertransformer/ directory, then run:
$kubectl apply -f model-storage-pvc.yml
- GPT-J
- GPT-NeoX
To use GRPC instead of HTTP, set
model_transaction_policy { decoupled: True }
in the download-weights-job-gpt-neox.yml configuration file.
Model job download
To deploy the job to download the model to the PVC, navigate to the kubernetes-cloud/online-inference/fastertransformer/ directory, then run:
$kubectl apply -f download-weights-job-gptj.yml
This job accomplishes the following:
- downloads the GPT-J weights into the PVC at
/mnt/pvc/models/gptj-store - installs the required packages to convert them to the FasterTransformer format
- converts the packages to the FasterTransformer format, then stores them in the PVC at
/mnt/pvc/gptj-store/triton-model-store/fastertransformer/1/, and - passes the
config.pbtxtfile to set important parameters, such as:tensor_para_size=1pipeline_para_size=1(1 GPU per 1 Pod), andmodel_transaction_policy { decoupled: False }, which allows for streaming if set toTrue.
The model is quite large at ~23Gi. It may take around 15-20 minutes for the download job to complete.
To check if the model has finished downloading, wait for the job to be in a Completed state:
$kubectl get jobsNAME COMPLETIONS DURATION AGEgptj-download 1/1 24m 1h
Or, follow the job logs to monitor progress:
$kubectl logs -l job-name=gptj-download --follow
Inference Service
To use GRPC or HTTP, ensure that the port is configured correctly in the file ft-inference-service-gptj.yml. Please uncomment the port you would like to use. Use only one port.
Once the model is downloaded, the InferenceService can be deployed by invoking:
$kubectl apply -f ft-inference-service-gptj.yml
Due to the size of the model, loading into GPU memory can take around 5-10 minutes. To monitor the progress of this, you can wait to see the KServe workers start in the pod logs by invoking:
$kubectl logs -f -l serving.kubeflow.org/inferenceservice=fastertransformer-triton-gptj kfserving-container
Alternatively, you can wait for the InferenceService to show that READY is True, and that it has a URL, such as in this example:
$kubectl get ksvcNAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGEfastertransformer-triton-gptj http://fastertransformer-triton-gptj.tenant-demo.knative.ord1.coreweave.cloud True 100 fastertransformer-triton-gptj-predictor-default-00001 2d5h
To use GRPC instead of HTTP, set
model_transaction_policy { decoupled: True }
in the download-weights-job-gpt-neox.yml configuration file.
Model job download
To deploy the job to download the model to the PVC, navigate to the kubernetes-cloud/online-inference/fastertransformer/ directory, then run:
$kubectl apply -f download-weights-job-gpt-neox.yml
This job accomplishes the following:
- downloads the GPT-NeoX weights into the PVC at
/mnt/pvc/models/gpt-neox - installs the required packages to convert them to the FasterTransformer format
- converts the packages to the FasterTransformer format, then stores them in the PVC at
/mnt/pvc/gptj-store/triton-model-store/fastertransformer/1/, and - passes the
config.pbtxtfile to set important parameters, such as:tensor_para_size=1pipeline_para_size=1(1 GPU per 1 Pod), andmodel_transaction_policy { decoupled: False }, which allows for streaming if set toTrue.
The model is quite large at ~39Gi (mirror to pull from Europe), and may take around 3-5 hours for the download and conversion job to complete.
To check if the model has finished downloading, wait for the job to be in a Completed state:
$kubectl get jobsNAME COMPLETIONS DURATION AGEgpt-neox-download 1/1 24m 1h
Or, follow the job logs to monitor progress:
$kubectl logs -l job-name=gpt-neox-download --follow
Inference Service
To use GRPC or HTTP, ensure that the port is configured correctly in the file ft-inference-service-neox.yml. Please uncomment the port you would like to use. Use one port.
Once the model is downloaded, the InferenceService can be deployed by invoking:
$kubectl apply -f ft-inference-service-neox.yml
Due to the size of the model, loading into GPU memory can take around 5-10 minutes. To monitor the progress of this, you can wait to see the KServe workers start in the pod logs by invoking:
$kubectl logs -f -l serving.kubeflow.org/inferenceservice=fastertransformer-triton-neox -c kfserving-container
Alternatively, you can wait for the InferenceService to show that READY is True, and that it has a URL:
$kubectl get ksvcNAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGEfastertransformer-triton-neox http://fastertransformer-triton-neox.tenant-demo.knative.ord1.coreweave.cloud True 100 fastertransformer-triton-neox-predictor-default-00001 5h54m
Using the Python Inference Client
Once you have the InferenceService up and running, you should be able to query FasterTransformer via the HTTP API to generate text based on a conditional prompt.
From the kubernetes-cloud/online-inference/fastertransformer/client directory, login to Docker:
$docker build -t $DOCKER_USER/fastertransformer-triton-client:1
Set the value for the SERVICE variable. When setting parameters:
- DO NOT append
http://to theSERVICEparameter below. - Use either the URL for the GPTJ or the URL for the GPT-Neox Inference Service for
--url - Use either the value
gptj or gpt-neoxfor the--modelparameter - Use either the value
httpORgrpcfor the--protocolparameter
For example:
$export SERVICE=fastertransformer-triton-gptj.tenant-demo.knative.ord1.coreweave.cloud
Run the image using HTTP
To run the image using --protocol=http, invoke the command respective to the model in use:
GPT-J
$docker run $DOCKER_USER/fastertransformer-client:1 --url=$SERVICE --model=gptj --protocol=http --prompt="Mary has a little lamb."
GPT NeoX
$docker run $DOCKER_USER/fastertransformer-triton-client:1 --url=$SERVICE --model=gpt-neox --protocol=http --prompt="Mary has a little lamb."
Run the image using GRPC
To run the image using --protocol=grpc, invoke the command respective to the model in use:
GPT-J
$docker run $DOCKER_USER/fastertransformer-client:1 --url=$SERVICE --model=gpt-neox --protocol=grpc --prompt="Mary has a little lamb."
GPT NeoX
$docker run $DOCKER_USER/fastertransformer-triton-client:1 --url=$SERVICE --model=gpt-neox --protocol=grpc --prompt="Mary has a little lamb."
Output
The invocation shown below should produce output that resembles the following (in this example, GRPC is used as the networking protocol):
$docker run $DOCKER_USER/fastertransformer-client:1 --url=$SERVICE --model=gptj --protocol=grpc --prompt="Mary has a little lamb."
This command produces the output:
Mary has a little lamb. Its fleece is white as snow, and everywhere that Mary walks, the lamb is sure to be sure-footed behind her. It loves the little lambs.
To set and change parameters, view the sample_request.json file.
example.py provides simple methods to use the Python Triton client with FasterTransformer via HTTP or GRPC.
Hardware and performance
GPT-J
This example is set to use one NVIDIA RTX A5000 PCIe GPU. CoreWeave has performed prior benchmarking to analyze performance of Triton with FasterTransformer against the vanilla Hugging Face version of GPTJ-6B.
Key observations
tokens_per_secondusing FasterTransformer GPTJ vs. Hugging Face on one A5000 GPU is about 30% faster in general.- Using multiple (four) GPUS, we have observed average speedups for GPTJ of 2X vs. 1 GPU on Hugging Face.
GPT-NeoX 20B
This example is set to use one NVIDIA RTX A6000 PCIe GPU. On a single A6000 GPU, the average tokens per second for a 1024 token input context is 15.6 tokens/second. For additional performance, FasterTransformer supports running over multiple GPUs.
Autoscaling
Scaling is controlled in the InferenceService configuration. This example is set to always run one replica, regardless of number of requests.
Increasing the number of maxReplicas will allow the CoreWeave infrastructure to automatically scale up replicas when there are multiple outstanding requests to your endpoints. Replicas will automatically be scaled down as demand decreases.
Example
spec:predictor:minReplicas: 1maxReplicas: 1
By setting minReplicas to 0, Scale-to-Zero can be enabled, which will completely scale down the InferenceService when there have been no requests for a period of time.
When a service is scaled to zero, no cost is incurred.
Please note that due to the size of the GPT-J model, Scale to Zero will lead to long request completion times if the model has to be scaled from zero. This can take around 5-10 minutes.
For more information on autoscaling, refer to the official Kubernetes documentation.