Real World Impact Benchmark
Compare Tensorizer using a real-world scenario
This benchmark tutorial constructs two identical services, one leveraging Tensorizer and the other leveraging a Hugging Face transformer to serve GPT-J-6B.
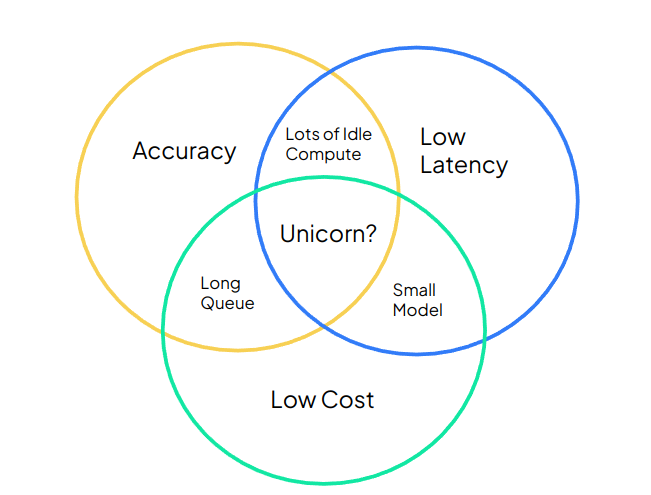
Serving traffic using machine learning models for inference requires a trade-off between cost, accuracy and latency. The illustration below showcases how one can optimize these metrics by using Tensorizer.
To learn more about Tensorizer before embarking on this tutorial, check out our blog post, "Decrease PyTorch Model Load Times with CoreWeave's Tensorizer," or our slideshow presentation of the same title.
Prerequisites
This guide presumes that kubectl and python are installed on the host system, and that the user has some basic familiarity with Kubernetes.
Example source code
To follow along with this tutorial, first clone the source code from CoreWeave's kubernetes-cloud repository.
Deploy all resources
After cloning the source code, change directories to tensorizer-isvc. From this directory, provision the Persistent Volume Claim (PVC) defined in pvc.yaml:
$kubectl apply -f pvc.yaml
Next, download the model to the newly deployed PVC by deploying the model download job located at model-download/model-download-job.yaml.
$kubectl apply -f model-download/model-download-job.yaml
Now, run the Hugging Face InferenceService by deploying its manifest at tensorizer_hf_isvc/kserve/hf-isvc.yaml. In this example, kserve is used as the server.
$kubectl apply -f tensorizer_hf_isvc/kserve/hf-isvc.yaml
Next, run the Tensorizer InferenceService by deploying the manifest at tensorizer_hf_isvc/kserve/tensorizer-isvc.yaml. In this example, kserve is once again used as the server.
$kubectl apply -f tensorizer_hf_isvc/kserve/tensorizer-isvc.yaml
Acquire the Inference Service's URL
View the InferenceService deployment's information to acquire its URL under the URL field using kubectl get:
$kubectl get ksvc
http:// may be required instead of https:// when connecting to the given URL.
Test the InferenceService
The KServe services use KServe's V1 protocol. The basic POST command below may be used to test the Service when served with KServe:
$curl http://<URL>/v1/models/gptj:predict -X POST -H 'Content-Type: application/json' -d '{"instances": ["Hello!"]}'
The Flask services simply encode queries into the URL path component. The basic curl command below may be used to test the Service when served with Flask:
$curl http://<URL>/predict/Hello%21
Run the benchmark
Use python to run the benchmark test. The load_test.py test defaults to running async requests with aiohttp. In this case, KServe is used as the server:
$python benchmark/load_test.py --kserve --url=<ISVC_URL> --requests=<NUMBER_OF_REQUESTS>
As an alternative to using requests, the --sync option may be added to the command line to send requests sequentially.
Delete the InferenceService
To remove the InferenceService, use kubectl delete to target the same manifest file applied earlier. For example:
$kubectl delete -f tensorizer_hf_isvc/<...>/<...>-isvc.yaml
InferenceServer containers
It is worth noting that each InferenceService manifest (those whose filenames end in -isvc.yaml) runs a container defined in a Dockerfile located in the same directory. For example, tensorizer_hf_isvc/kserve/Dockerfile.
These containers may be changed and rebuilt to customize the behavior of the InferenceService. The build context for each Dockerfile is its parent directory. Build commands are subsequently structured as follows:
$docker build ./tensorizer_hf_isvc -f ./tensorizer_hf_isvc/kserve/Dockerfile$docker build ./tensorizer_hf_isvc -f ./tensorizer_hf_isvc/flask/Dockerfile
Results
RAM Usage
Tensorizer uses only an amount of RAM that is equal to the size of the largest tensor to load the model directly into GPU in "Plaid" mode. As models get larger, the cost-effectiveness of using Tensorizer becomes more prevalent, as the entire model does not need to be loaded into CPU RAM before transferring it to the GPU. Therefore, scaling inference services during bursts of traffic minimizes costs for RAM.
Model load times
CoreWeave's Tensorizer outperforms SafeTensors and Hugging Face for model load times on OPT-30B with NVIDIA A100s.
Here, "model load times" refers to completely initializing the model from a checkpoint - not swapping in weights from a checkpoint to an already initialized model.
Smaller model metrics
CoreWeave's Tensorizer outperforms SafeTensors and HuggingFace for model load times on GPT-J-6B with NVIDIA A40s.
.f01a876.1200.png)
Larger model metrics
CoreWeave's Tensorizer outperforms SafeTensors and HuggingFace for model load times on OPT-30B with NVIDIA A100s.
.0a75c83.1200.png)
Handling burst requests
In CoreWeave's tests of Tensorizer's performance, CoreWeave's Tensorizer presented approximately five times faster average latency over the burst in requests, and required fewer Pod spin-ups compared to Hugging Face.
The burst involved 100 concurrent requests on GPT-J using NVIDIA A40s.
In these results, the data shown reflects how the InferenceService scaled from 1 idle GPU with zero requests to 100 requests sent at once. the InferenceService ran on NVIDIA A40s.
.8ec9a36.1200.png)
The average latency per request is 0.43s for Tensorizer end-to-end inference on GPT-Jm, as compared to 2.45 seconds. Tensorizer provides cost effectiveness, lower latency and minimal RAM usage as model size gets larger.