Fine-tune Large Language Models with CoreWeave Cloud
Use Argo Workflows to orchestrate the fine-tuning
Introduction
This guide demonstrates how to fine-tune a Large Language Model (LLM) using a custom dataset with CoreWeave Cloud. It serves as a practical example of a starter project but is not intended to be a comprehensive production application in its current form.
Fine-tuning an LLM can be costly; however, this guide illustrates how to utilize CoreWeave's architecture with Argo Workflows to automatically scale down to zero active pods after completing the fine-tuning process. This releases the billable computation resources, making this a cost-effective system.
Features
The scenario in this guide fine-tunes the EleutherAI Pythia model on a single GPU, and can be extended with several advanced features:
- Scalable configuration: Run up to 8 GPUs on the same node, and adjust the RAM and number of CPUs.
- Model variety: This fine-tuner can automatically downloads model from Hugging Face, or use an uploaded model.
- Prompt testing: Characterize the model during fine-tuning by periodically running a prompt file against it and logging the results.
The fine-tuner uses PyTorch 2.0, CUDA 11.8, and the latest version of DeepSpeed. It also supports CUDA 12.0-based images.
Hardware configuration
The default configuration uses 8 vCPUs, 128GB RAM, and a single NVIDIA A40 or A6000 with 48GB VRAM. This cost-effective and optimized configuration costs about $2.00 per hour with CoreWeave's resource-based pricing and is best suited for models with 155 million to 6 billion parameters.
After fine-tuning, this workflow can optionally deploy an inference endpoint configured with 4 vCPUs, 8GB RAM, and a single NVIDIA RTX A5000 with 24GB VRAM. This setup can efficiently perform inference on models with 6 billion parameters and is much more affordable than the fine-tuning configuration, at approximately $0.85 per hour.
If more performance is desired, use workflow parameters to scale up the number of GPUs, RAM, and vCPUs.
Prerequisite steps
Before proceeding with this demonstration, please complete these preliminary steps:
- Configure CoreWeave Kubernetes
- Install Argo Workflows
- Retrieve the Bearer token and log into the Argo web UI
- Install Argo CLI
Once those are complete, proceed with the steps below.
Download the source code repository
In a working folder, download and extract the demonstration code to your local workstation. The following command works in macOS, Linux, and Windows CMD, but not Windows PowerShell.
$curl -L https://github.com/coreweave/kubernetes-cloud/archive/refs/heads/master.tar.gz | tar xzf -
Alternatively, clone the kubernetes-cloud GitHub repository with your preferred method.
Then, change to the repository's finetuner-workflow directory.
Create a PVC
The demonstration uses a shared filesystem called a PVC (Persistent Volume Claim) for storing the base model, fine-tuning data, and sharing them between multiple fine-tune runs.
Create the PVC using one of the two options below.
Option 1: Create the PVC with kubectl
To create the PVC, apply the finetune-pvc.yaml manifest with kubectl and confirm the PVC was created successfully.
$kubectl apply -f finetune-pvc.yaml
Result:
persistentvolumeclaim/finetune-data created
The manifest has reasonable defaults, but if it requires editing, keep the following points in mind:
- HDD storage is preferred over NVMe. It's more cost-effective and the fine-tuner does not need high I/O performance.
- The model checkpoints require between 1024 and 2048 GB of storage. If more space is needed later, it's simple to expand it in place.
- By default, the workflow expects a PVC named
finetune-data. If this changes, remember to adjust thepvcparameter accordingly.
Option 2: Create the PVC with CoreWeave Cloud
For an interactive experience, create the PVC in a web browser.
Navigate to Storage Volumes in CoreWeave Cloud.
Click New Volume, and enter the requested fields:
- Volume Name: finetune-data
- Region: Chicago - ORD1
- Disk Class: HDD
- Storage Type: Shared Filesystem
- Size (Gi): Choose a size between 1024 and 2048 Gi
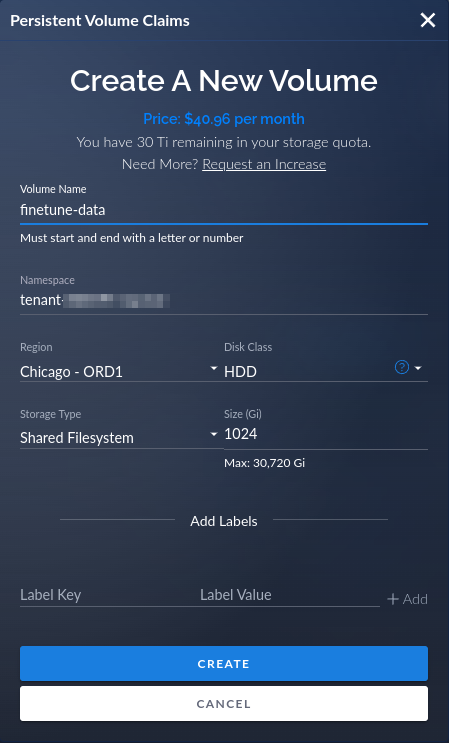
Click Create and verify that the PVC is created successfully.
Optional: Deploy a Filebrowser app
The filebrowser app provides an easy way to transfer data to and from the PVC created in the previous step.
It's also possible to use a Virtual Server to load files onto the PVC. This flexibility represents one of CoreWeave's key advantages.
- Navigate to CoreWeave Applications, and then click the Catalog tab.
- Locate
filebrowserand click Deploy. - Assign it a short name, such as
finetune, to avoid SSL CNAME issues - Select the ORD1 location.
- Hover over
finetune-datain Available Volumes to reveal the+icon, and click it to attach the volume. Ensure that it is mounted, as demonstrated in the example below. - Click Deploy.
.79199d6.753.png)
Load the fine-tuning dataset
Connect to the PVC using the filebrowser application, or use a virtual server.
Create a directory on the PVC called dataset, then load the fine-tuning files into that directory.
The data should be in individual plain text files with a .txt extension and in the exact format desired for prompts and responses. When the workflow runs, Argo will tokenize the dataset using a fast Golang component.
Partition the data into separate files to make it easier to add and remove subsets. When loading multiple datasets, create a meaningful directory name for each.
If using a different top-level directory name than dataset, change the dataset parameter to match before invoking the workflow.
About the repository files
This is an inventory of the files in the finetuner-workflow directory of the coreweave/kubernetes-cloud repository, cloned earlier in this guide.
| Filename | Description |
|---|---|
finetune-workflow.yaml | The Argo workflow itself. Many parameters at the top of this file are discussed later. |
finetune-pvc.yaml | The PVC declaration applied in the prerequisites section of this guide. |
finetune-role.yaml | The ServiceAccount role used by Argo. |
finetuner/Dockerfile | A Dockerfile used to build a fine-tuner image after modifying the finetuner.py code. |
finetuner/ds_config.json | The deepspeed configuration placed in the container. We recommend not modifying this. |
finetuner/evaluator.py | Prompt testing functions |
finetuner/finetuner.py | The simple reference example fine-tune training code. |
finetuner/inference.py | Inference endpoint |
finetuner/requirements.txt | The Python requirements and versions. It's possible to create a venv, but this is mainly for the Dockerfile build. |
finetuner/utils.py | Utility classes for the fine-tuner. |
Set up the ServiceAccount
The workflow requires a ServiceAccount, Role, and a RoleBinding. Create those by applying the finetune-role.yaml manifest.
$kubectl apply -f finetune-role.yaml
Output:
serviceaccount/finetune createdrole.rbac.authorization.k8s.io/role:finetune createdrolebinding.rbac.authorization.k8s.io/rolebinding:finetune-finetune created
Run Argo Workflows
Most of the parameters defined in finetune-workflow.yaml have default values which can be overridden as needed and don't need to be specified.
The run_name parameter is required. Make this unique and short because it's used for the InferenceService DNS name.
Here's an example that sets run_name to my-example and runs an inference service when fine-tuning is complete.
$argo submit finetune-workflow.yaml \-p run_name=my-example \-p run_inference=true \--serviceaccount finetune
Expand to see the example output:
Click to expand - Example output
Name: finetune-bl5f2Namespace: tenant-96362f-devServiceAccount: inferenceStatus: PendingCreated: Tue Apr 18 18:15:52 -0400 (now)Progress:Parameters:run_name: my-examplerun_inference: truepvc: finetune-datamodel: EleutherAI/pythia-2.8b-dedupeddataset: datasetretokenize: falsetokenizer:reorder:sampling: 100eot_token:pad_token:boundary_token: \nboundary_index: -1context: 2048prompt_file:prompt_every: 0prompt_tokens: 200prompt_samples: 5top_k: 50top_p: 0.95temperature: 1repetition_penalty: 1.1train_ratio: 0.9batch_size: -1force_fp16: falsebatch_size_divisor: 1.0random_seed: 42learn_rate: 5e-5epochs: 1gradients: 5zero_stage: 3no_resume: falselogs: logswandb_key:project_id: huggingfaceinference_only: falseregion: ORD1trainer_gpu: A40trainer_gpus: 1trainer_cores: 8trainer_ram: 192inference_gpu: RTX_A5000model_downloader_image: ghcr.io/wbrown/gpt_bpe/model_downloadermodel_downloader_tag: 73cceb0tokenizer_image: ghcr.io/wbrown/gpt_bpe/dataset_tokenizertokenizer_tag: 73cceb0finetuner_image: gooseai/finetunerfinetuner_tag: cuda-11-8-torch-2-rc10inference_image: coreweave/ml-imagesinference_tag: pytorch-huggingface-81d5ce11
Common parameters
The finetune-workflow.yaml manifest has many adjustable parameters. The table below lists the parameters that are most commonly adjusted.
| Parameter | Description | Default Value |
|---|---|---|
run_name | Required: Used for DNS and inference service names. Make this unique and short. The results are stored in results-<run_name>. | None |
dataset | PVC dataset directory | dataset |
reorder | Sort the input text files by size_ascending, size_descending, name_ascending, name_descending, random, none, or shuffle. Note: shuffle sorts the path using the none format, but also randomizes the order of tokens, which is useful for large sequential datasets, such as novels. This is different from the trainer shuffling, which selects contexts randomly. When using an option other than shuffle or none, we recommend passing -no_shuffle to the trainer. | none |
run_inference | Start an test inference service when the fine-tuning exercise is done. This is not intended for production use. | false |
inference_only | If true, skip fine-tuning and only run the inference endpoint. Set this to false on the first run. | false |
pvc | PVC name to use for the dataset and model artifacts. | finetune-data |
region | The CoreWeave region. Generally, this should be ORD1. | ORD1 |
dataset | Dataset directory relative to the pvc root. | dataset |
context | Training context size in tokens. Affects the tokenization process as well. | 2048 |
epochs | Number of times the fine-tuner should train on the dataset. | 1 |
learn_rate | How quickly the model should learn the fine-tune data. Too high a learn rate can be counterproductive and replace the base model's training. | 5e-5 |
wandb_key | Strongly recommended. Use an API key from http://wandb.ai to report on fine-tuning metrics with nice charts. | None |
Parameters that adjust hardware
To adjust performance, modify these hardware parameters.
| Parameter | Description | Default Value |
|---|---|---|
trainer_gpu | Type of training GPU | A40 |
trainer_gpus | Number of training GPUs | Default: 1. Valid Range is 1 to 7. |
inference_gpu | Type of inference GPU | RTX_A5000 |
trainer_cores | Number of vCPU cores | 8 |
trainer_ram | Gigabytes of RAM | 192 |
How to change base models
The fine-tuner supports models that use the Hugging Face AutoModelForCausalLM transformer class.
The default model is EleutherAI/pythia-2.8-deduped. To change models, specify the Hugging Face model identifier to download. Models are cached in the PVC cache directory.
If a custom model is uploaded, specify the model's path from the PVC root.
| Parameter | Description | Default Value |
|---|---|---|
model | Model identifier, or path to an uploaded model. | EleutherAI/pythia-2.8b-deduped |
The fine-tuner assumes the model's tokenization format is BPE (Byte Pair Encoding), a common subword tokenization technique.
Parameters for prompt testing
It's often useful to characterize a model during fine-tuning, so the demonstration accepts a prompt file to periodically run against the model. The results are sent to Weights and Biases (wandb) and logged. The top_k, top_p, temperature, and repetition_penalty parameters are also adjustable.
To use prompt testing, set these parameters.
| Parameter | Description | Default Value |
|---|---|---|
prompt_file | Prompts file to read when testing the model and reporting the outputs. This is useful for monitoring the progress and training effectiveness. One prompt per line, newlines escaped with \n if the prompt is multi-line. | none |
prompt_every | Interval of step counts to run the prompts tests. If 0, it will perform these tests at each checkpoint. | 0 |
prompt_tokens | Number of tokens to generate per prompt. | 200 |
prompt_samples | Number of times to evaluate each prompt. | 5 |
top_k | Sampling parameter used during prompt evaluation. | 50 |
top_p | Sampling parameter used during prompt evaluation. | 0.95 |
temperature | Sampling parameter used during prompt evaluation. | 1.0 |
repetition_penalty | Sampling parameter used during prompt evaluation. | 1.1 |
Other invocation methods
We've shown how to set workflow parameters on the command line, but there are other methods available.
Click to expand - How to use a parameters file
To use a parameters file, create finetune_params.yaml.
run_name: my-exampledataset: datasetreorder: randomrun_inference: trueinference_only: falsemodel: EleutherAI/pythia-2.8b-deduped
Then, modify the command line to use the --parameter-file option:
$argo submit finetune-workflow.yaml \--parameter-file finetune_params.yaml \--serviceaccount finetune
Click to expand - How to use the web UI
- Navigate to your Argo Workflows deployment in the Applications Catalog.
- Navigate to the Access URL, found at the top of the page.
- Paste the Bearer token in the client authentication field, then click Login.
- Click Submit new workflow.
- Upload
finetune-workflow.yaml, or paste the contents into the Workflow text area. - In the Parameters section, modify the values according to your requirements.
- In the Service Account field, enter:
finetune. - Click Submit.
Click to expand - How to use the API
To use the Argo Workflows API, you'll use a tool like curl to send an HTTP request to the Argo server.
First, convert your workflow from YAML to JSON with argo list.
$argo list -o json finetune-workflow.yaml > finetune-workflow.json
Next, create a JSON file with the parameter values you want to submit:
{"run_name": "my-example","dataset": "dataset","reorder": "random","run_inference": "true","inference_only": "false","model": "EleutherAI/pythia-2.8b-deduped","serviceaccount": "finetune"}
Submit the workflow to the API with curl.
$curl -X POST -H "Content-Type: application/json" \-H "Authorization: Bearer <the-token>" \-d @finetune-workflow.json \--data-urlencode [email protected] \http://<argo-server-address>/api/v1/workflows/<namespace>/submit
- Replace
<the-token>with the Bearer token you retrieved in the prerequisites section. - Replace
<argo-server-address>with the Access URL of the Argo server. - Replace
<namespace>with your workflow namespace.
You can find the namespace by running:
$kubectl get deployments | grep argo-serverfine-tuner-argo-server 1/1 1 1 3d20h
The namespace in this example is fine-tuner-argo-server.
Click to expand - How to use Helm charts
To use a Helm chart, first create a new directory.
$mkdir finetune-helm-chart$cd finetune-helm-chart
Then, initialize the chart. This command generates a basic Helm chart structure in the finetune directory.
$helm create finetune
Move your existing finetune-workflow.yaml file into the templates directory within the finetune Helm chart.
$mv ../finetune-workflow.yaml finetune/templates/
Create values.yaml in the finetune directory with the same parameters as the original Argo command line, plus the serviceaccount value.
run_name: my-exampledataset: datasetreorder: randomrun_inference: trueinference_only: falsemodel: EleutherAI/pythia-2.8b-dedupedserviceaccount: finetune
Modify the finetune-workflow.yaml file in the templates directory to use Helm chart parameters as desired. This is a simplified example of the parameter syntax, do not copy and paste this directly.
apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata:generateName: "finetune-"spec:entrypoint: main# Example Helm parameter syntaxarguments:parameters:- name: run_namevalue: {{ .Values.run_name }}- name: datasetvalue: {{ .Values.dataset }}- name: reordervalue: {{ .Values.reorder }}- name: run_inferencevalue: {{ .Values.run_inference }}- name: inference_onlyvalue: {{ .Values.inference_only }}- name: modelvalue: {{ .Values.model }}serviceAccountName: {{ .Values.serviceaccount }}
Install the Helm chart with the helm install command:
$helm install finetune-release ./finetune
This will deploy the workflow with the values from values.yaml.
More options
To customize the parameter values when deploying the Helm chart, either update the values.yaml file directly or use the --set option with the helm install command. For example:
$helm install finetune-release ./finetune \--set run_name=new-example,dataset=new-dataset
This deploys the workflow and uses the --set option to override the corresponding values in values.yaml.
Use the web UI to observe the workflow
Navigate to the Argo Workflows deployment in the Applications Catalog, then click the Access URL at the top of the page to open the login screen.
The deployment may require up to 5 minutes to request a TLS certificate. If an HTTPS security warning occurs, please wait for the certificate to be installed.
Paste the Bearer token, which was retrieved in the prerequisites section, into the client authentication box then click Login.
.37d246f.1200.png)
Navigate to the Workflows menu to see the progress as it goes through the tokenization, fine-tune, and inference stages.
.b2ba587.1200.png)
Use the Argo CLI to observe the workflow
To instruct Argo to observe the workflow progress in the CLI, add --watch to the command line.
$argo submit finetune-workflow.yaml \-p run_name=my-example \-p run_inference=true \--serviceaccount finetune \--watch
To attach to a running workflow and observe it, first locate the workflow name.
$argo list
Then, watch the workflow. Substitute the workflow name where indicated.
$argo watch <workflow name>
The output is similar to this:
Click to expand - Argo watch output
Name: finetune-bl5f2Namespace: tenant-96362f-devServiceAccount: inferenceStatus: FailedMessage: child 'finetune-bl5f2-4194046320' failedConditions:PodRunning FalseCompleted TrueCreated: Tue Apr 18 18:15:52 -0400 (2 minutes ago)Started: Tue Apr 18 18:15:52 -0400 (2 minutes ago)Finished: Tue Apr 18 18:17:12 -0400 (1 minute ago)Duration: 1 minute 20 secondsProgress: 1/3ResourcesDuration: 1m18s*(1 cpu),4m3s*(100Mi memory)Parameters:run_name: my-exampledownload_dataset: truerun_inference: truepvc: finetune-datamodel: EleutherAI/pythia-2.8b-dedupeddataset: datasetretokenize: falsetokenizer:reorder:sampling: 100eot_token:pad_token:boundary_token: \nboundary_index: -1context: 2048prompt_file:prompt_every: 0prompt_tokens: 200prompt_samples: 5top_k: 50top_p: 0.95temperature: 1repetition_penalty: 1.1train_ratio: 0.9batch_size: -1force_fp16: falsebatch_size_divisor: 1.0random_seed: 42learn_rate: 5e-5epochs: 1gradients: 5zero_stage: 3no_resume: falselogs: logswandb_key:project_id: huggingfaceinference_only: falseregion: ORD1trainer_gpu: A40trainer_gpus: 1trainer_cores: 8trainer_ram: 192inference_gpu: RTX_A5000model_downloader_image: ghcr.io/wbrown/gpt_bpe/model_downloadermodel_downloader_tag: 73cceb0tokenizer_image: ghcr.io/wbrown/gpt_bpe/dataset_tokenizertokenizer_tag: 73cceb0dataset_downloader_image: ghcr.io/coreweave/dataset-downloader/smashwords-downloaderdataset_downloader_tag: 7dba2c7finetuner_image: gooseai/finetunerfinetuner_tag: cuda-11-8-torch-2-rc10inference_image: coreweave/ml-imagesinference_tag: pytorch-huggingface-81d5ce11STEP TEMPLATE PODNAME DURATION MESSAGE● finetune-bl5f2 main├───✔ tokenizer(0) model-tokenizer finetune-bl5f2-2169410118 7s└───● finetuner model-finetuner finetune-bl5f2-3837635091 1h
During fine-tuning, the time elapsed is displayed, along with the expected completion time. Checkpointing and loss reporting are also provided.
View Argo logs
If the process appears to hang at the message Loading the model, this is a known bug in the terminal display that can happen while downloading the model.
To fix this, kill the workflow job and resubmit it. The display issue should not reoccur after the first download.
To view the logs, run the following command and substitute the workflow name where indicated.
$argo logs <workflow-name>
Artifacts and Inference
After fine-tuning is complete, the tuned model is in the /finetunes/{{run_name}}/final directory of the PVC. It can be downloaded directly, or if the inference service was deployed, query the new model from the inference service URL.
If KNative CLI is installed, discover the service URL with:
$kn service list
Otherwise, use kubectl:
$kubectl get ksvcNAME URL LATEST AGE CONDITIONS READY REASONinference-western-predictor-default http://inference-western-predictor-default.tenant-example.knative.chi.coreweave.com inference-western-predictor-default-00007 2d21h 3 OK / 3 True
Then, with the URL available and jq installed, use curl to run a test query:
$curl -XPOST -H "Content-type: application/json" -d '{"prompt": "She danced with him in the honky-tonk"}' 'http://inference-western-predictor-default.tenant-example.knative.chi.coreweave.com/completion' |jq .
That should return a result similar to:
% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed100 935 100 828 100 107 147 19 0:00:05 0:00:05 --:--:-- 188{"generated_text": "She danced with him in the honky-tonk hall as if to say, \"You got me into this mess. Now I'll get you out of it. Let's split it and go our separate ways. Maybe I'll get lucky and make you my partner.\"\nHe grinned. \"You never know. Don't let anyone stop you. But if someone tries to arrest you, let them worry about that.\"\n\"I'll do that. Now, about that money?\"\n\"Money? What money?\"\n\"The loan they paid to your uncle to buy your brother out of that mine. I'm not sure why they did that.\"\nHe grinned. \"That's what I've been trying to figure out myself. They want more power over the land they're buying so they can put up cattle. But they're not taking long to figure out that I'm onto them, so keep this money safe until we figure out the best way to handle it. Don't try"}
Summary
These are the basic steps for downloading a base model, tokenizing a dataset, fine-tuning the model, and running test inferences against the new model. Even though this just begins to explore the capabilities of fine-tuning, it provides a solid starting point and a guide to inspire more production projects.